这两天在R软件中发现了一种趣味横生的检测异常值的可视化方法叫bagplot,我翻译为“布袋图”。它首先定义一个二维数据的中心,然后,将与中心较为疏离的点定义为野值。
以经典的car数据为例演示下布袋图的用法:
library(aplpack);
library(rpart);
cardata<-car.test.frame[,6:7];
par(mfrow=c(1,1))
bagplot(cardata,verbose=F,factor=3,show.baghull=T,
dkmethod=2,show.loophull=T,precision=1)
title("car data Chambers/Hastie 1992")
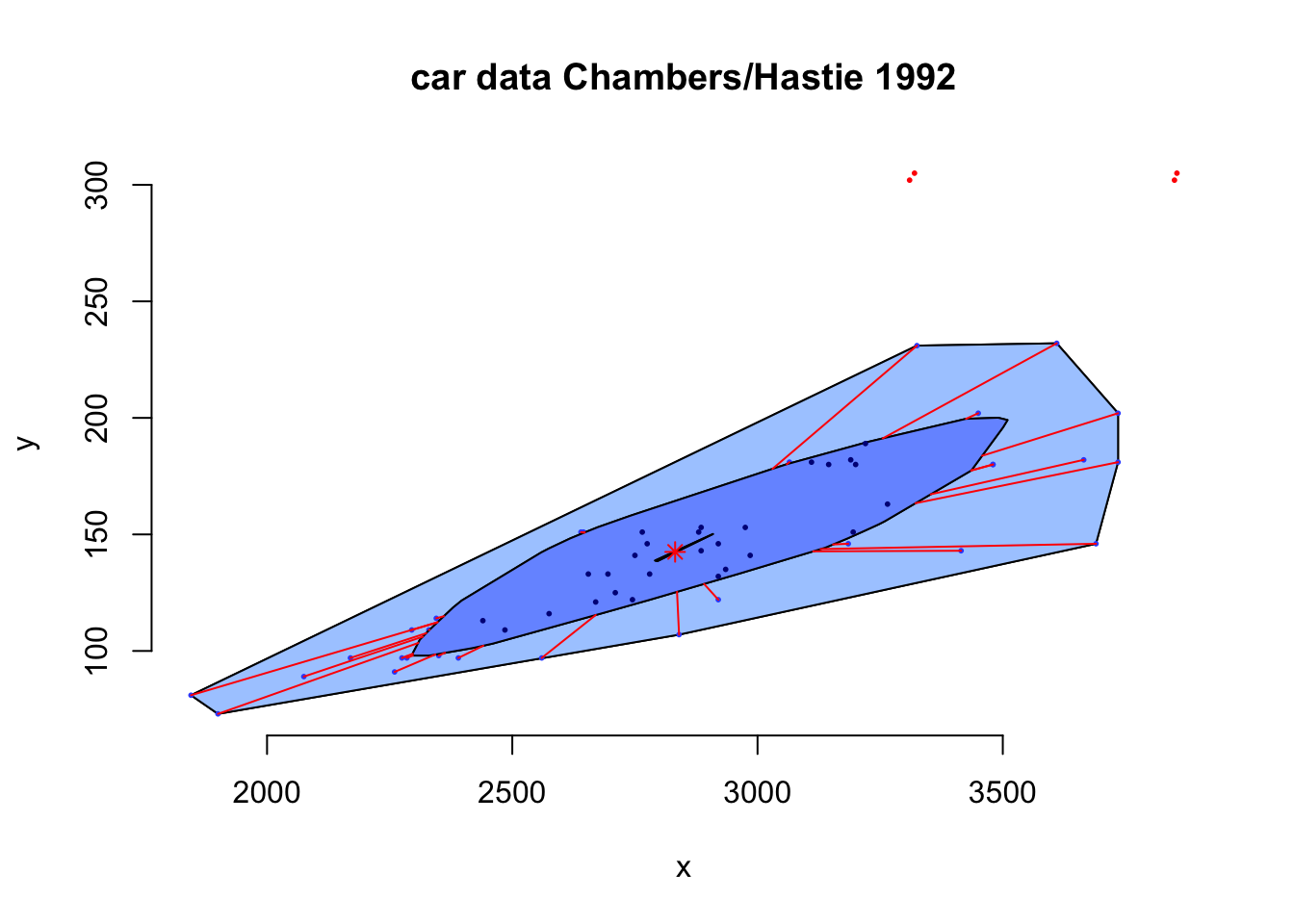
可以看到图形右上角有一些偏离中心较远的点被染成了血红色,那就是布袋图眼中的野值。
如果随机生成一个正态数据,对应的布袋图会是什么样子?
seed=222;
set.seed(seed);
n=200;
data=rnorm(n,mean=0);
datan<-cbind(data,c(rnorm(n-2,mean=20),10,30));
datan[,2]<-datan[,2]*300;
bagplot(datan,factor=3,create.plot=T,approx.limit=300,
show.outlier=T,show.looppoints=T,
show.bagpoints=T,dkmethod=2,
show.whiskers=T,show.loophull=T,
show.baghull=T,verbose=F)
title(paste("seed: ",seed,"/ n: ",n));
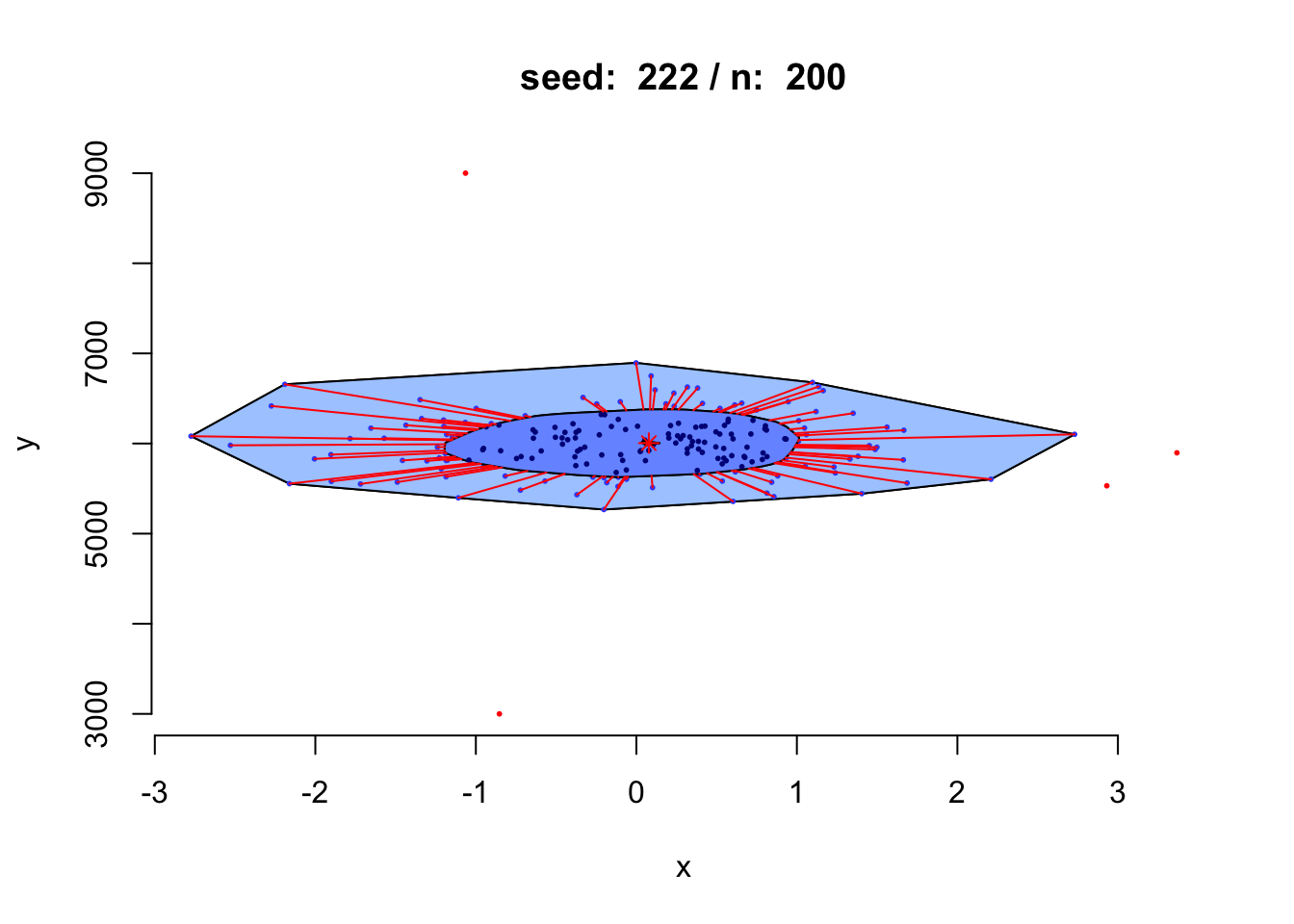
我们增加数据规模看看会是什么效果。
seed <- 194
n <- 3000
set.seed(seed)
data <- rnorm(n)
datan<-cbind(data,c(rnorm(n-2,mean=76,sd=20),105,50));
datan[,2]<-datan[,2]*300
bagplot(datan,factor=3,create.plot=T,approx.limit=300,
show.outlier=T,show.looppoints=T,
show.bagpoints=T,dkmethod=2,
show.whiskers=T,show.loophull=T,
show.baghull=T,verbose=F)
title(paste("seed: ",seed,"/ n: ",n))
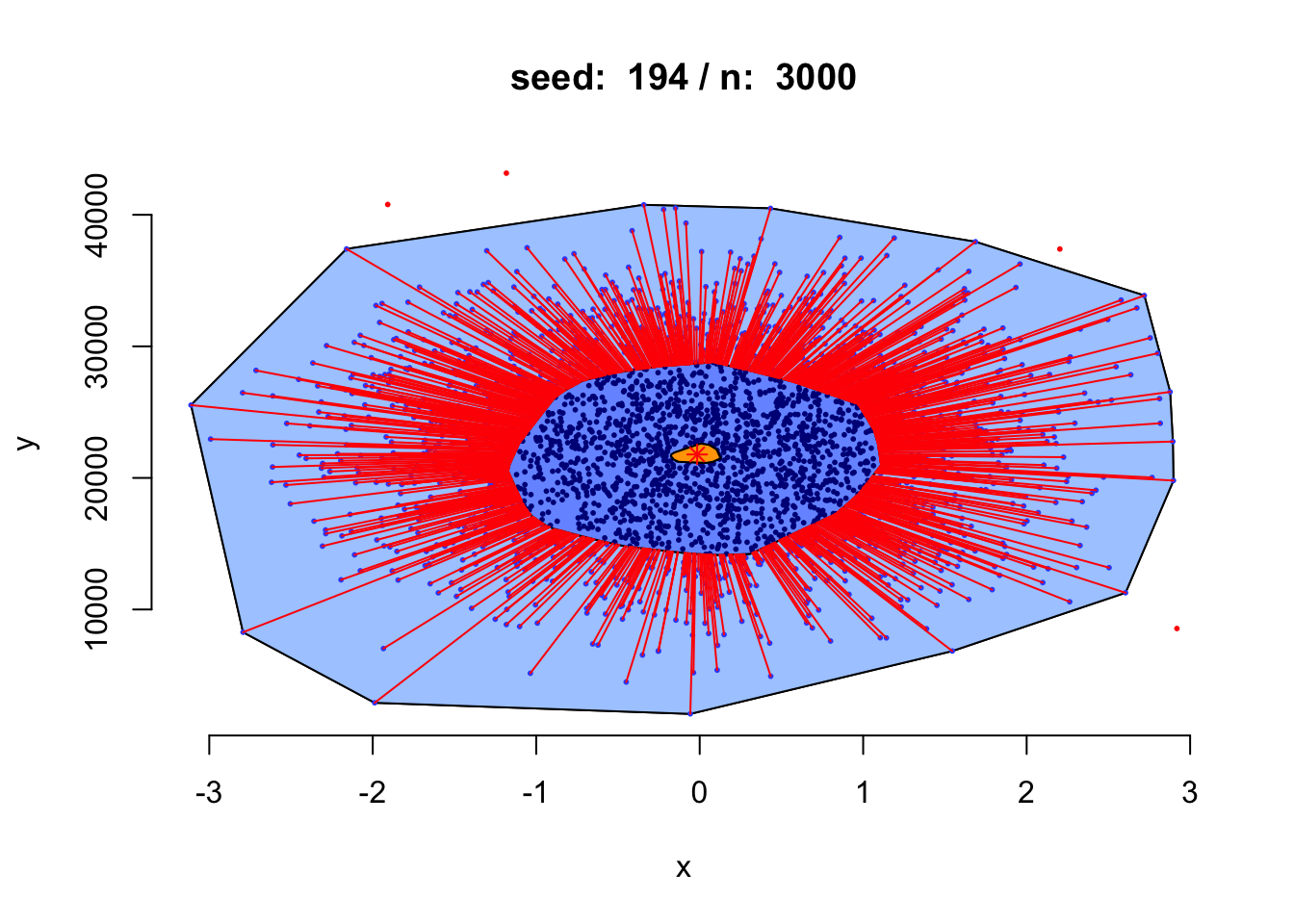
像一颗海胆。
其他异常值检测方法
除了布袋图之外,还有很多异常值的识别方法,这些方法大致可以分为可视化方法、模型方法和经验方法三类。
可视化方法
可视化方法识别异常值是最直观的一种方法了。常用的图形主要包括箱线图、QQ图、直方图、密度图、小提琴图、布袋图、散点图、热力图以及局部离群因子(LOF)得分图。
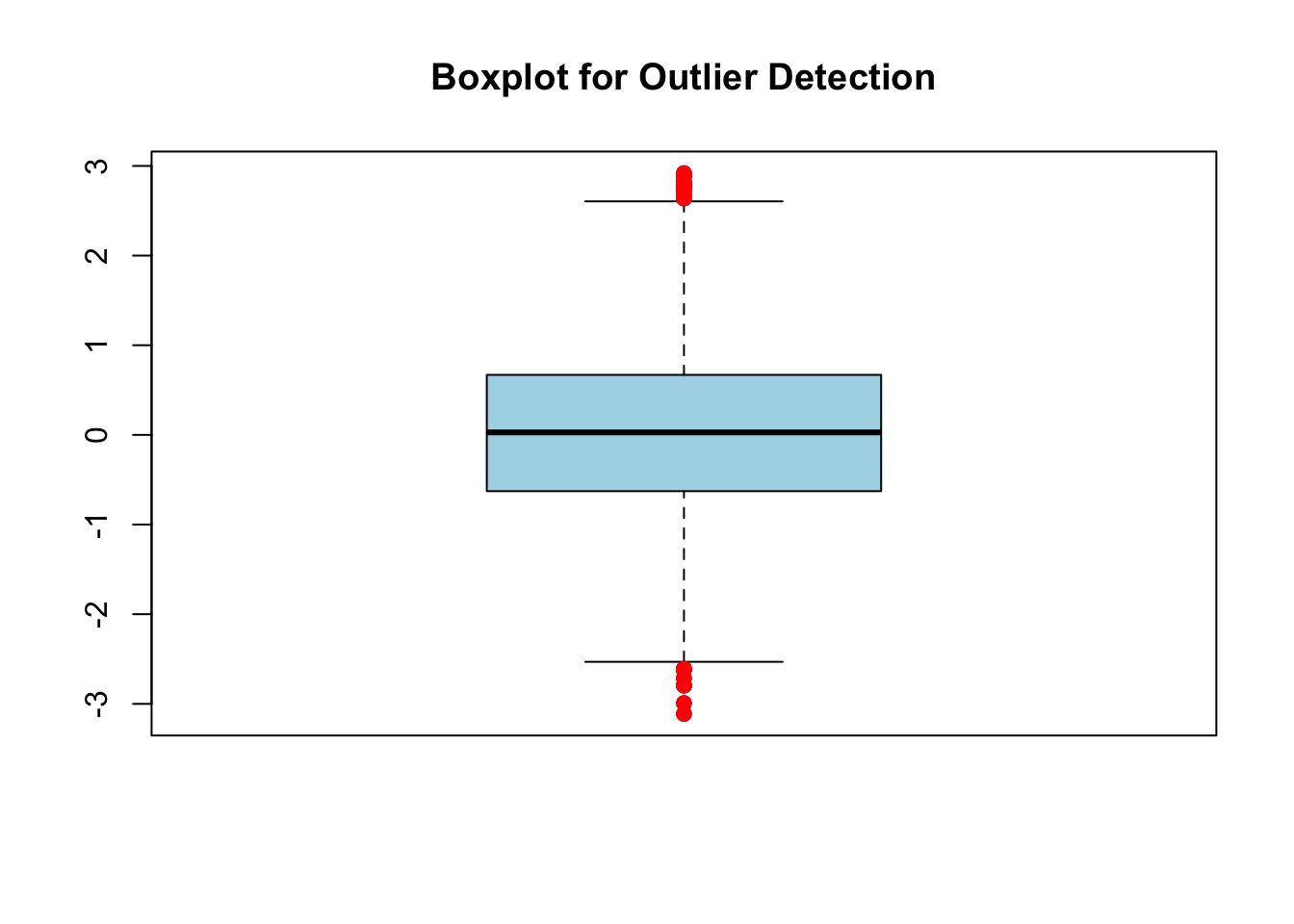
箱线图
# 箱线图
boxplot(data, main = "Boxplot for Outlier Detection", col = "lightblue")
# 添加异常值标记
outliers <- boxplot.stats(data)$out
points(rep(1, length(outliers)), outliers, col = "red", pch = 19)
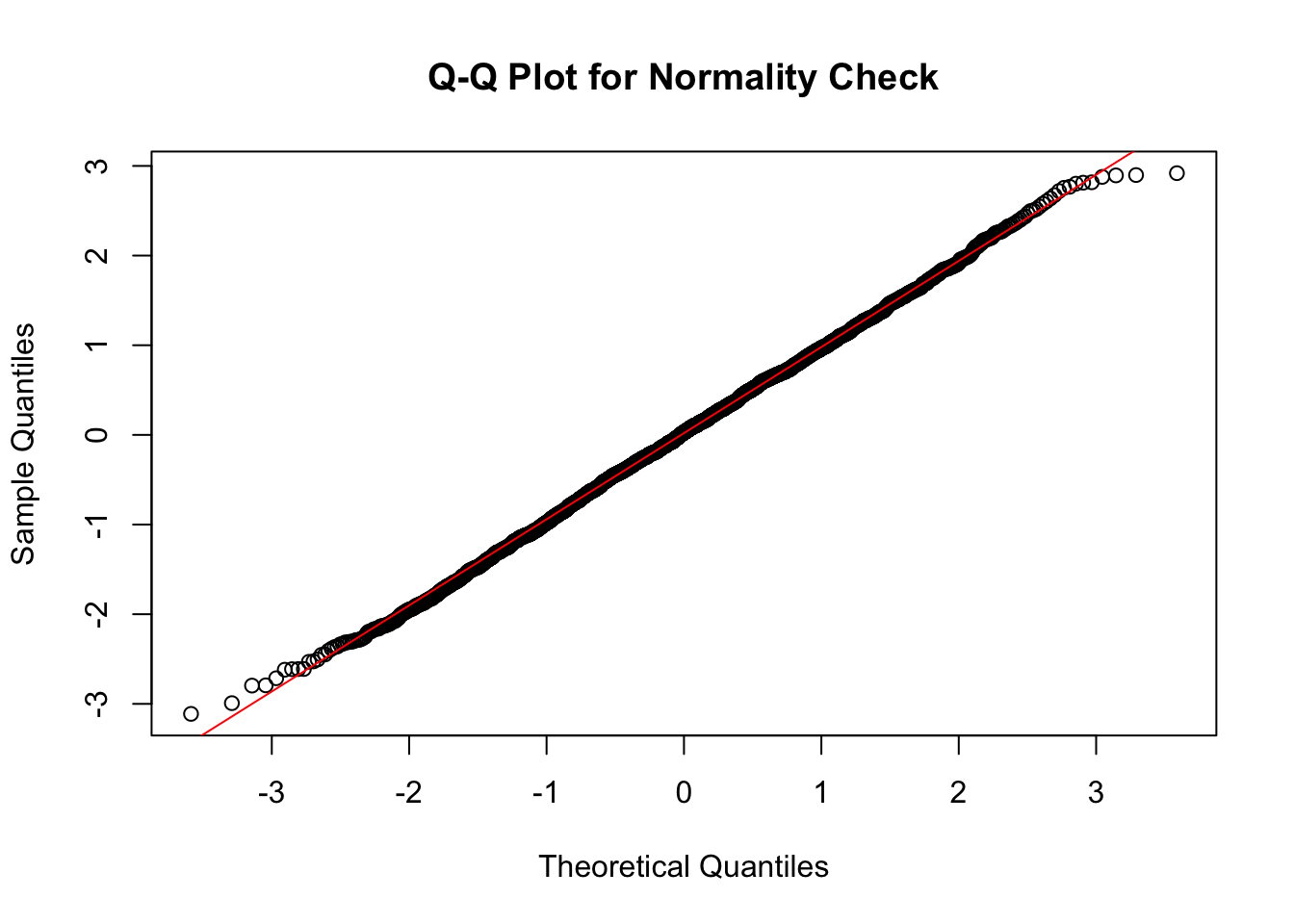
QQ图
qqnorm(data, main = "Q-Q Plot for Normality Check")
qqline(data, col = "red")
# 标出异常值
qq_outliers <- data[abs(scale(data)) > 3]
points(which(data %in% qq_outliers), qq_outliers, col = "red", pch = 19)
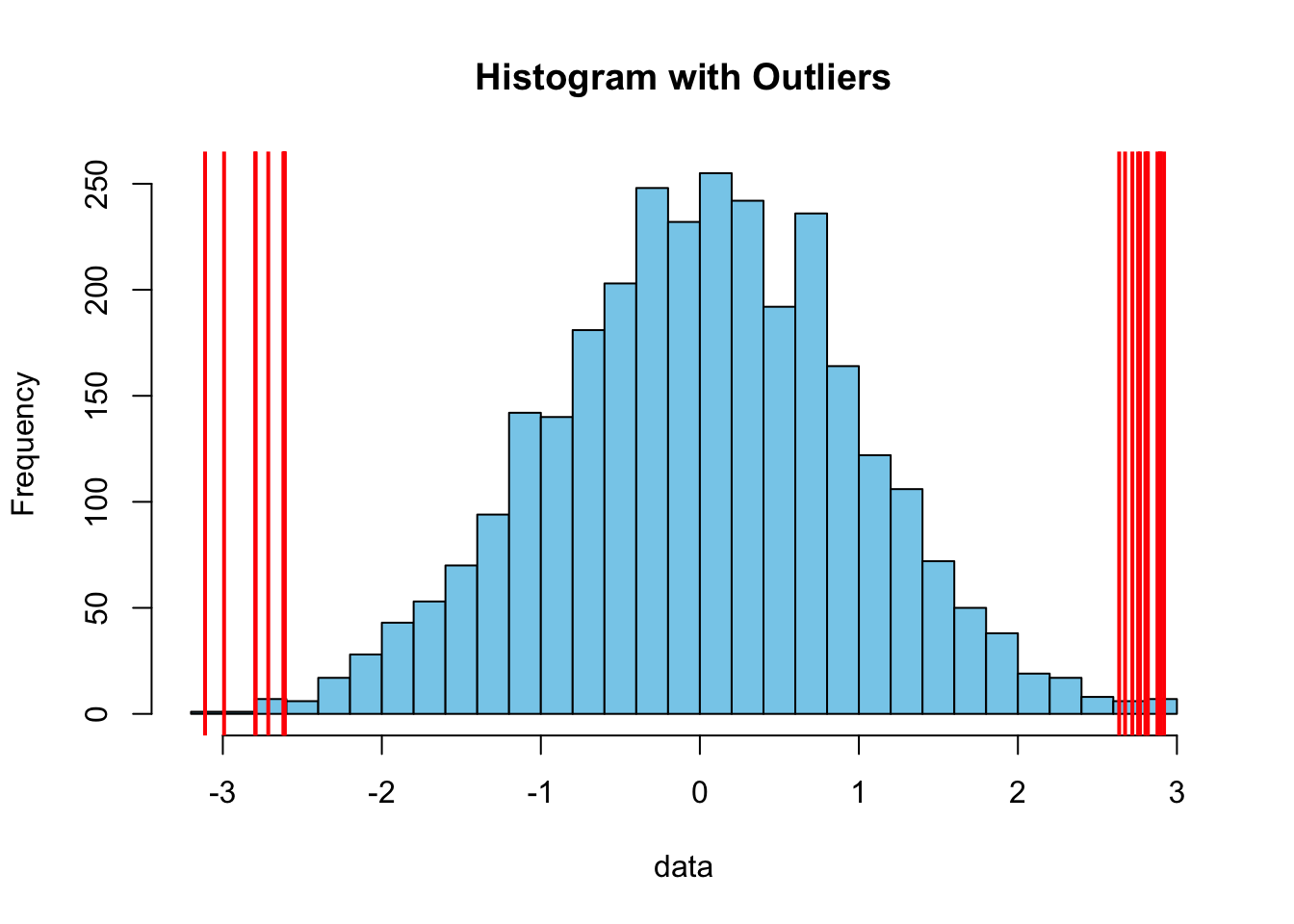
直方图
hist(data, breaks = 30, col = "skyblue", main = "Histogram with Outliers")
abline(v = outliers, col = "red", lwd = 2)
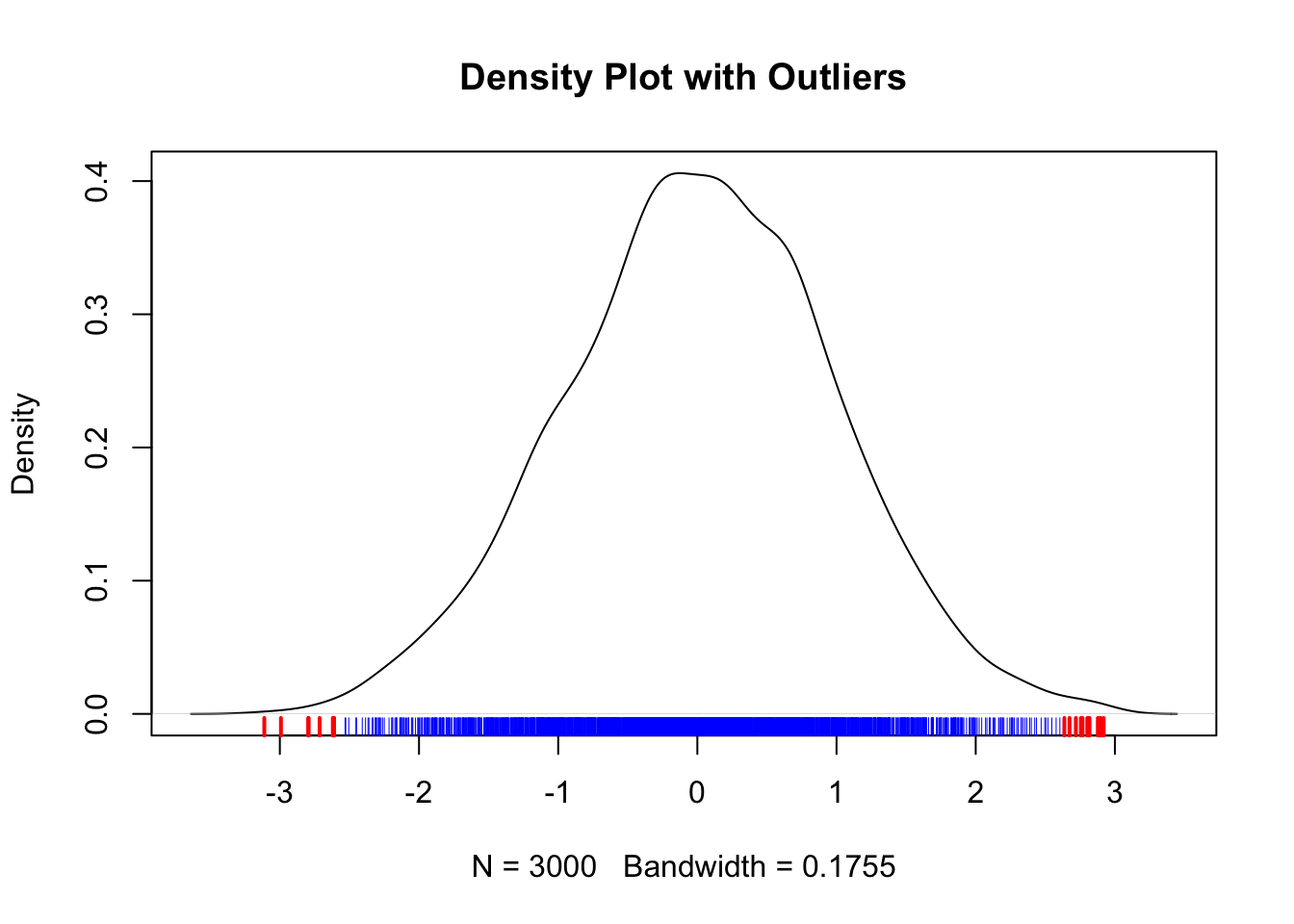
密度图
# 密度图
plot(density(data), main = "Density Plot with Outliers")
rug(data, col = "blue")
rug(outliers, col = "red", lwd = 2)
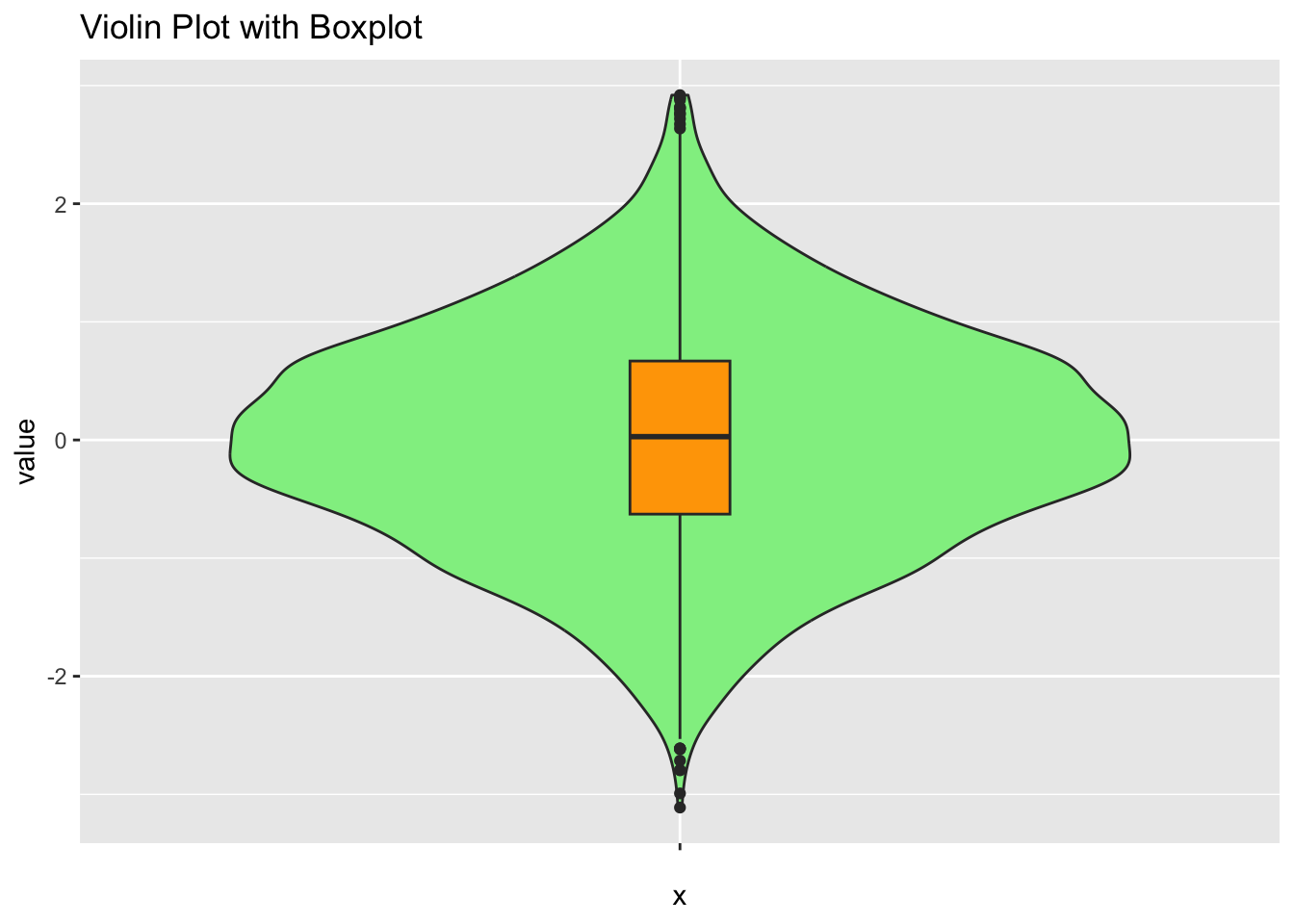
小提琴图
# 使用ggplot2
library(ggplot2)
ggplot(data.frame(value = data), aes(x = "", y = value)) +
geom_violin(fill = "lightgreen") +
geom_boxplot(width = 0.1, fill = "orange") +
ggtitle("Violin Plot with Boxplot")
布袋图
见本文开篇内容,不赘述。
散点图/分布图
# 生成含异常值的双变量数据
set.seed(123)
x <- rnorm(100)
y <- x + rnorm(100, sd = 0.5)
x[101:102] <- c(4, -3) # 插入异常值
y[101:102] <- c(5, -4)
# 基础散点图
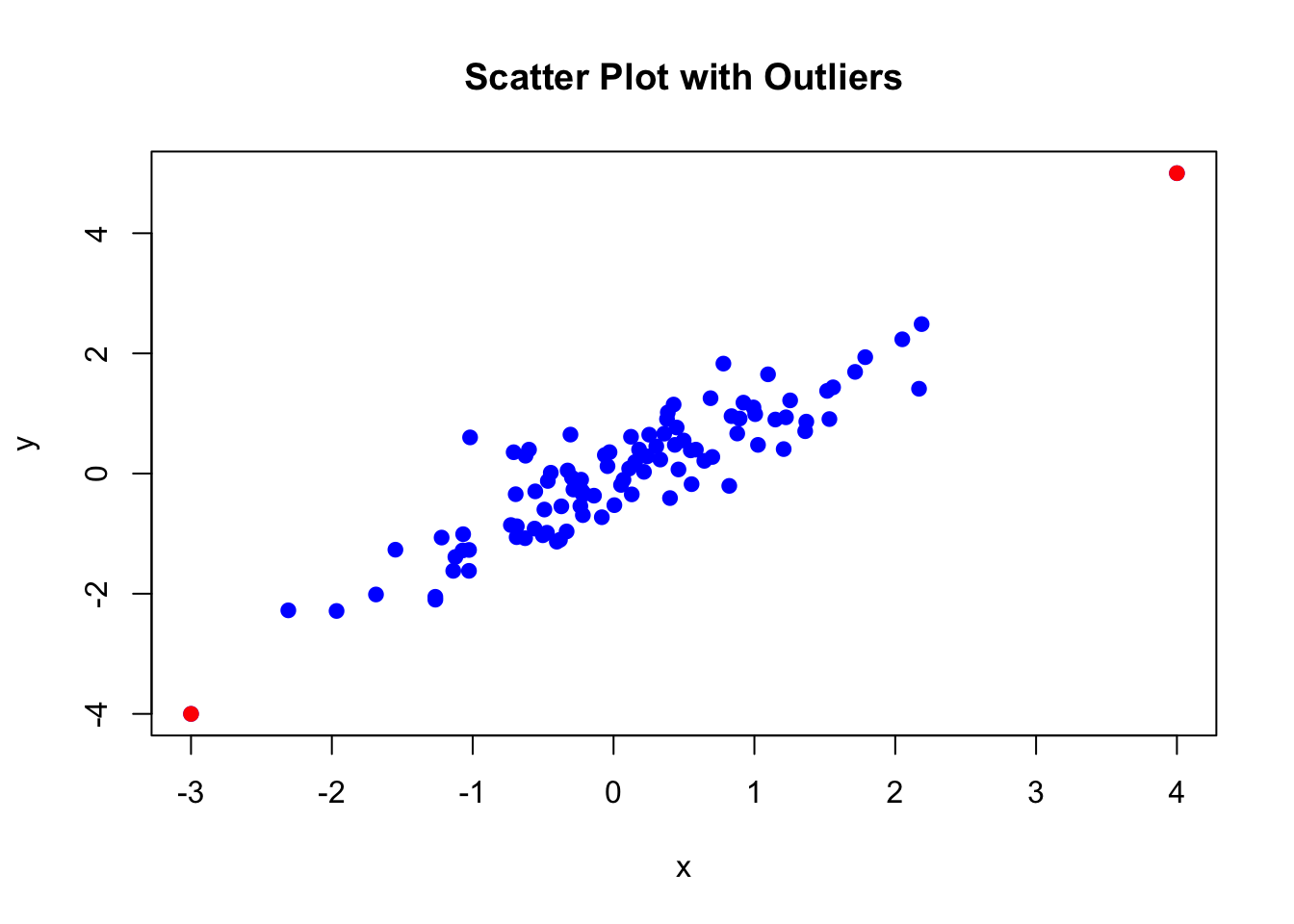
plot(x, y, pch = 19, col = "blue", main = "Scatter Plot with Outliers")
outliers <- data.frame(x = x[101:102], y = y[101:102])
points(outliers$x, outliers$y, col = "red", pch = 19)
# 使用ggplot2
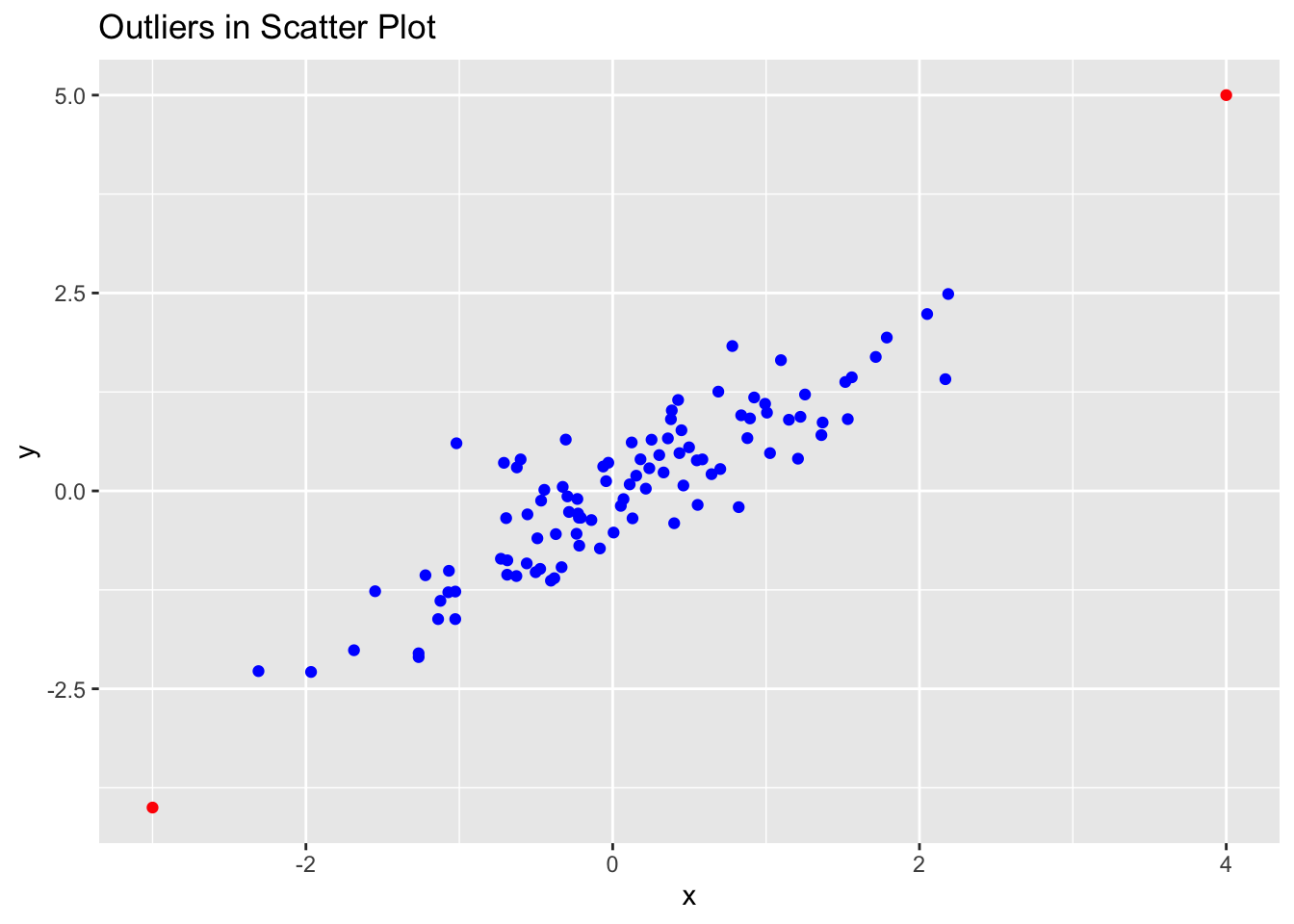
df <- data.frame(x, y)
ggplot(df, aes(x, y)) +
geom_point(color = ifelse(1:nrow(df) %in% 101:102, "red", "blue")) +
ggtitle("Outliers in Scatter Plot")
# 使用GGally包
library(GGally)
## Registered S3 method overwritten by 'GGally':
## method from
## +.gg ggplot2
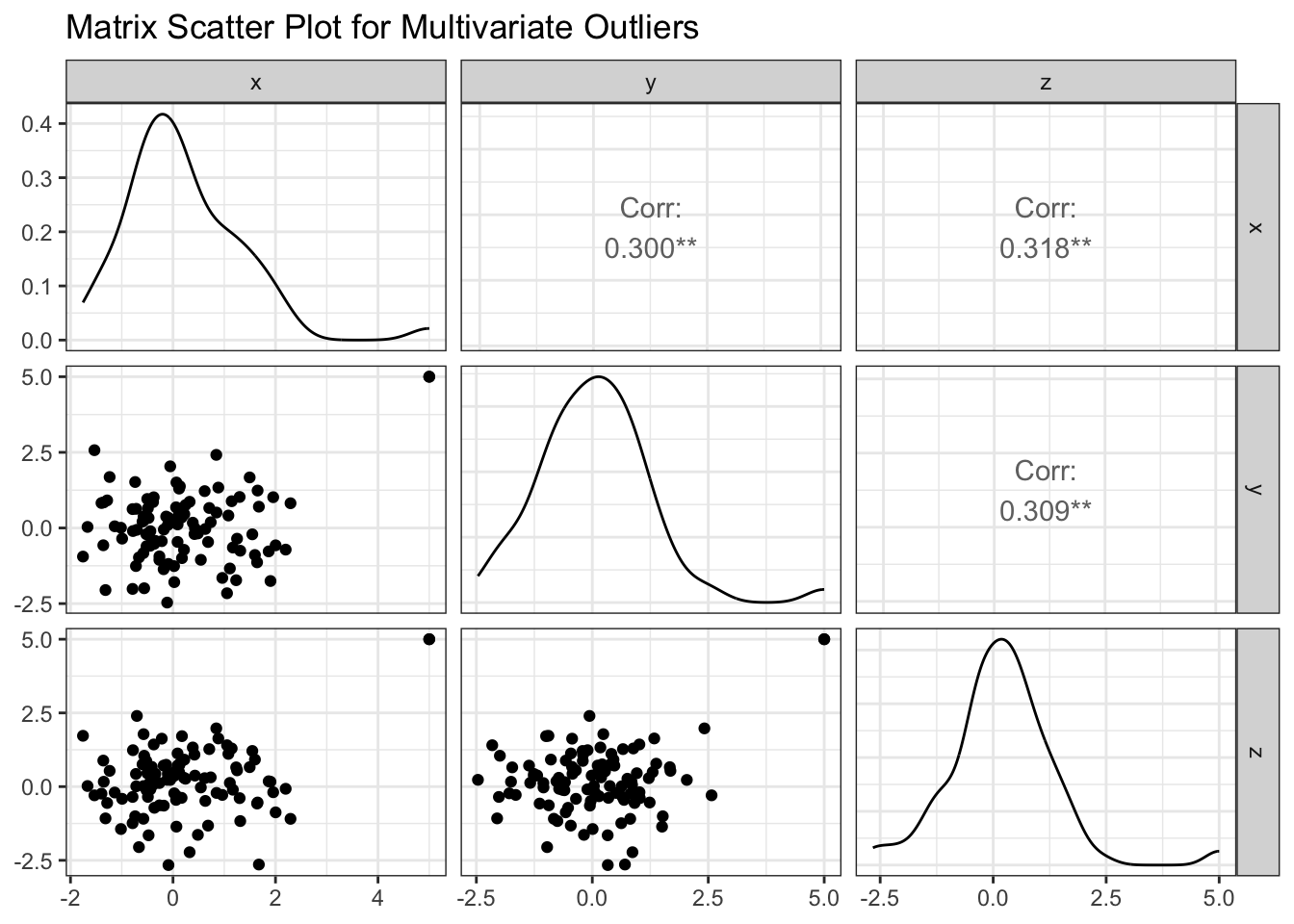
df <- data.frame(x = rnorm(100), y = rnorm(100), z = rnorm(100))
df[101:102, ] <- c(5, 5, 5) # 插入异常值
ggpairs(df) +
theme_bw() +
ggtitle("Matrix Scatter Plot for Multivariate Outliers")
热力图
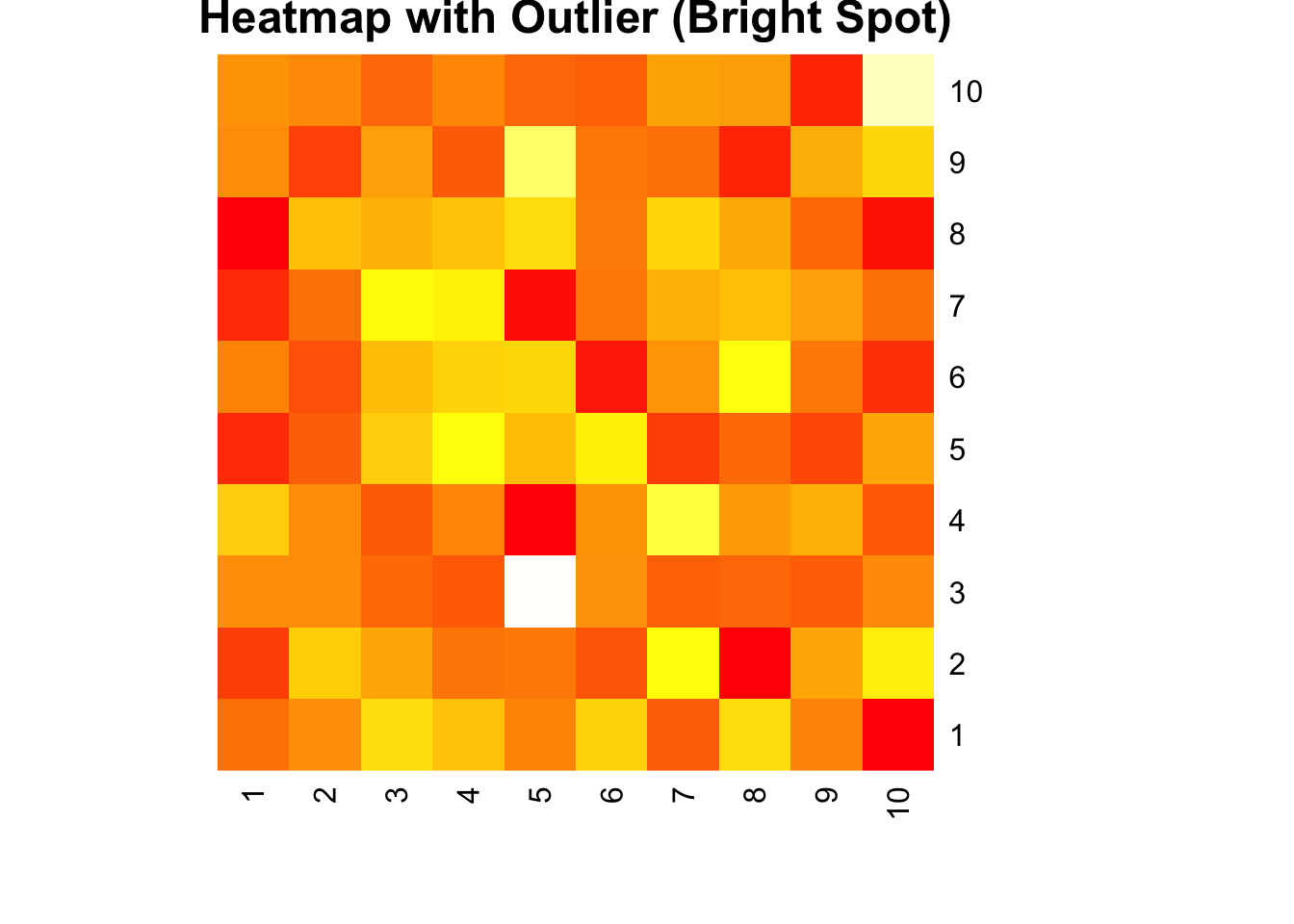
# 生成含异常值的矩阵数据
mat <- matrix(rnorm(100), nrow = 10)
mat[3, 5] <- 10 # 插入异常值
heatmap(mat, Colv = NA, Rowv = NA, col = heat.colors(256),
main = "Heatmap with Outlier (Bright Spot)")
局部离群因子(LOF)得分图
# 使用DMwR2包
library(DMwR2)
## Registered S3 method overwritten by 'quantmod':
## method from
## as.zoo.data.frame zoo
lof_scores <- lofactor(data, k = 5) # 计算LOF得分
plot(data, col = ifelse(lof_scores > 1.5, "red", "blue"),
pch = 19, main = "LOF Outlier Scores")
legend("topright", legend = c("Outlier", "Normal"),
col = c("red", "blue"), pch = 19)
模型方法
模型方法主要包括统计分析方法和机器学习方法。统计分析方法主要是利用一些常见的统计量作为指标来生成一些正常值的甄别标准,以此标准来甄别异常值。
统计分析法
常用的统计分析方法主要包括$3\sigma$方法和四分位距。
3西格玛准则
\(3\sigma\) 准则的应用十分简明,即将超过均值三个标准差的数据全都视为异常值。下面看一个例子:
# 生成示例数据
set.seed(123)
data <- rnorm(100)
data[20] <- 10 # 插入异常值
# 3西格玛准则识别
mean_val <- mean(data)
sd_val <- sd(data)
outliers_3sigma <- data[abs(data - mean_val) > 3*sd_val]
cat("3西格玛准则识别的异常值:", outliers_3sigma, "\n")
## 3西格玛准则识别的异常值: 10
四分位距
四分位距方法是根据上四分之一分位数和下四分之一分位数生成一个正常域,把超出正常域的数值视为异常值,具体算法见代码:
# IQR法识别
Q1 <- quantile(data, 0.25)
Q3 <- quantile(data, 0.75)
IQR_val <- Q3 - Q1
lower_bound <- Q1 - 1.5 * IQR_val
upper_bound <- Q3 + 1.5 * IQR_val
outliers_iqr <- data[data < lower_bound | data > upper_bound]
cat("IQR法识别的异常值:", outliers_iqr)
## IQR法识别的异常值: 10
机器学习方法
最常用的甄别异常值的机器学习方法是聚类分析。
聚类分析
# K-means聚类识别异常值
data(USArrests)
data <- USArrests
kmeans_model <- kmeans(data, centers = 2)
cluster_centers <- kmeans_model$centers
distances <- sqrt(rowSums((data - cluster_centers[kmeans_model$cluster])^2))
outliers_cluster <- data[distances > quantile(distances, 0.95),]
异常值的意义和处理
识别异常值只是万里长征第一步。更重要的是找到异常值出现的原因,到底是录入错误还是背后有深刻的原因。如果是录入错误可以重新补正或者干脆删除了之,当然也可以进行插值处理。值得注意的是背后有驱动原因的异常值。譬如,对于上市公司的股票价格而言,每一个异常的股票价格背后可能都对应了一个值得研究学习的事件,而类似的事件如果经常发生的话,就可以利用它构建一个事件驱动策略。