支持向量机(Support Vector Machine,SVM)是Corinna Cortes和Vapnik等于1995年首先提出的一种机器学习方法,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等 其他机器学习问题中。
通俗的介绍一下这个过程:
我们有一些数据点,这些数据点是n维实空间中的点。我们希望能够把这些点通过一个n-1维的超平面分开。通常这个被称为线性分类器。有很多分类器都符合这个要求。但是我们还希望找到分类最佳的平面,即使得属 于两个不同类的数据点间隔最大的那个面,该面亦称为最大间隔超平面。如果我们能够找到这个面,那么这个分类器就称为最大间隔分类器。
理解了上面这段话就可以理解支持向量机了。支持向量机是将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。在分开数据的超平面的两边建有两个互相平行的超平面。建立方向合适的分隔超平面使两个与之平行的超平面间的距离最大化。其假定为,平行超平面间的距离或差距越大,分类器的总误差越小。而所谓支持向量是指那些在间隔区边缘的训练样本点。这里的“机(machine,机器)”实际上是一个算法。在机器学习领域,常把一些算法看做是一个机器。
学习支持向量机知识的一个极好指南是C.J.CBurges的《模式识别支持向量机指南》。
目前,R中已经实现了支持向量机算法(相关的包有e1071包、kernlab包、klar包和svmpath包。以数据iris和cats为例加以说明:
library(e1071)
library(MASS)
data(cats)
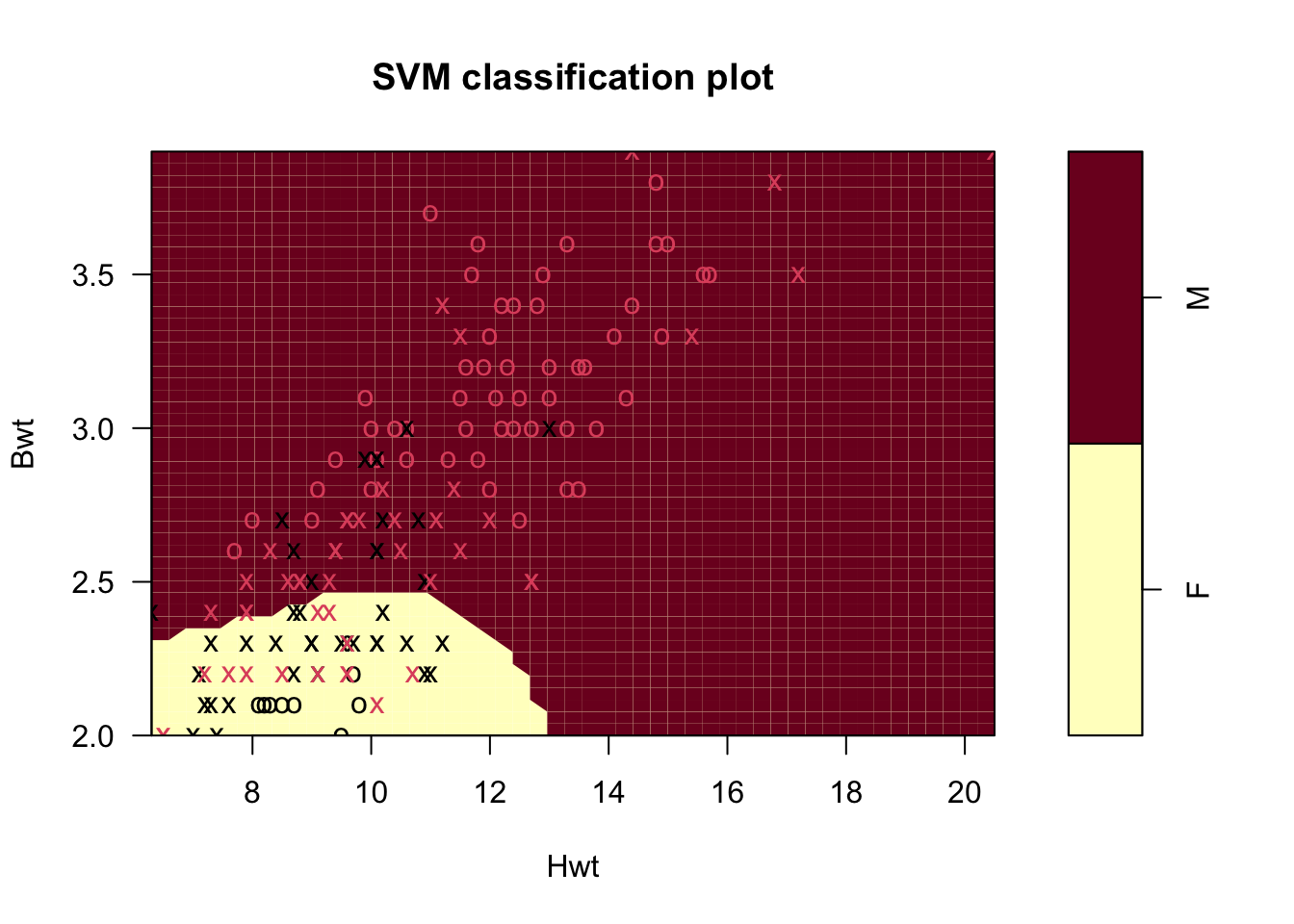
m= svm(Sex~., data = cats)
plot(m, cats)
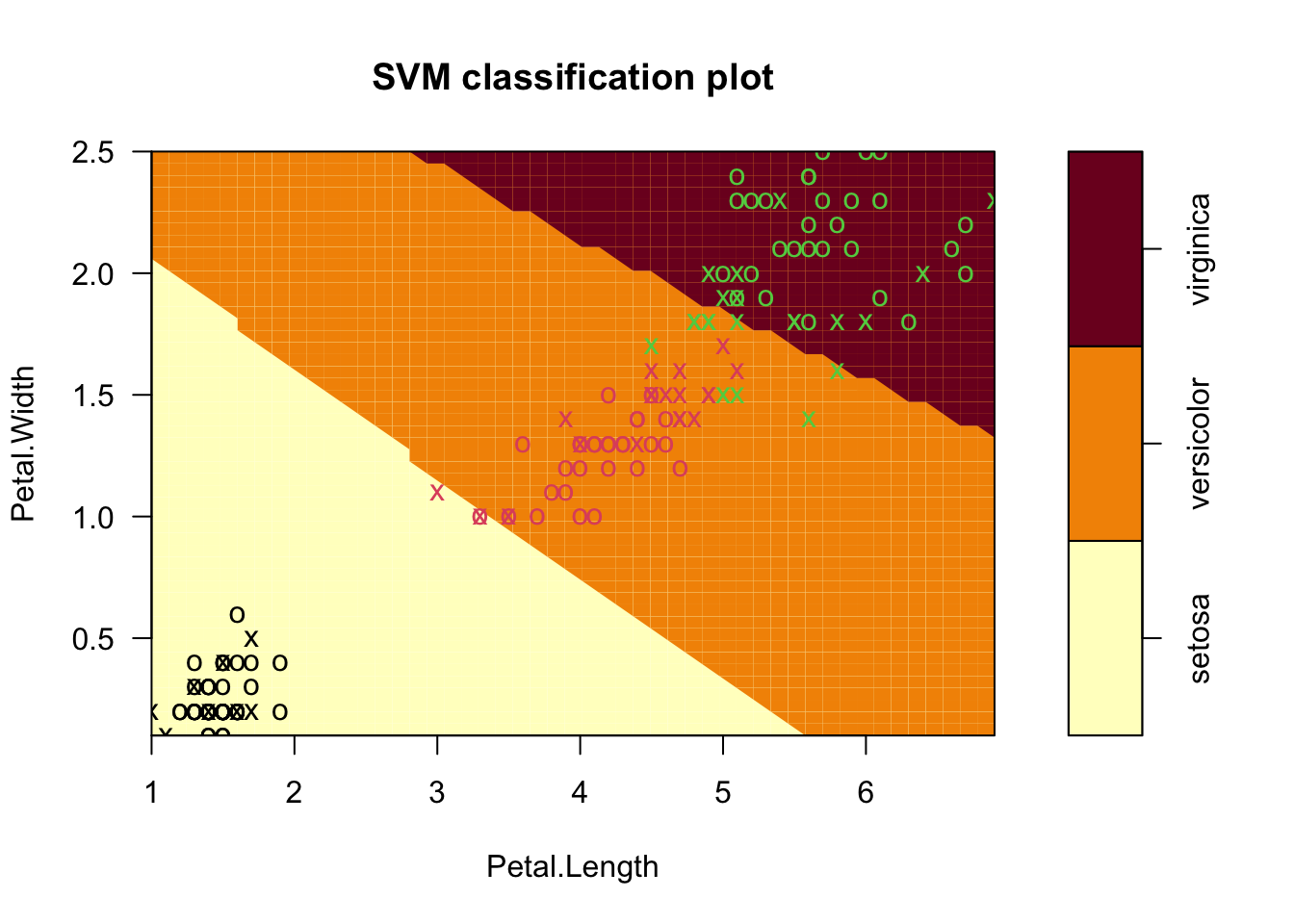
data(iris)
m2=svm(Species~., data = iris)
plot(m2, iris, Petal.Width ~ Petal.Length, slice = list(Sepal.Width = 3, Sepal.Length = 4))
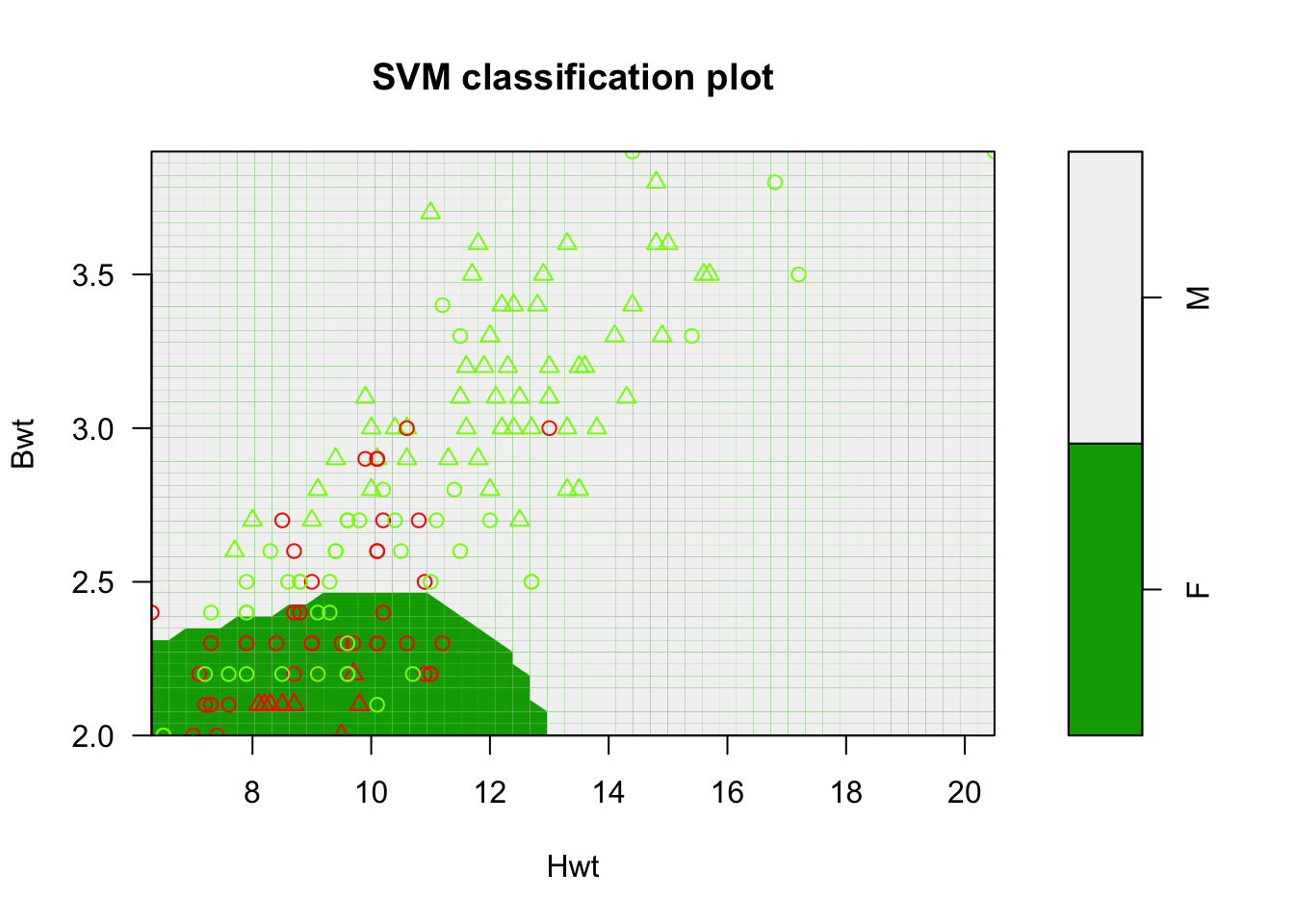
plot(m, cats, svSymbol = 1, dataSymbol = 2, symbolPalette = rainbow(4),color.palette =terrain.colors)
支持向量机还可以用到股票价格的预测上,具体案例回头再写。