R软件是处理时间序列的利器。之所以这么说主要是基于两点:一是R软件中的时间序列模型异常丰富,已经将从计量经济学的良心arma到garch族模型到VAR模型以及时间序列结构变异点诊断等一网打尽;二是R软件中的时间序列对象的类型也足够丰富,可以让我们随心所欲地处理规则时间序列和不规则时间序列,以及让不规则时间序列拥有规则的时间属性。以上种种方便都让我们在处理经济和金融时间序列时更加得心应手。
目前,R中已有的时间序列相关包如下。
| 时序类型 | 对象类型 | 索引类型 | R包 |
| 规则时间序列 | ts | Date | stat包 |
| 不规则时间序列 | timeSeries | timeDate | timeSeries(fSeries) |
| 不规则时间序列 | its | POSIXct | its包 |
| 不规则时间序列 | irts | POSIXct | tseries包 |
| 各种 | zoo | zoo包 | |
| 各种 | xts | xts包 |
第一个是stat包。RCore们在stat包中定义了R语言中最古典的时间序列对象类型,即ts类型。想必用R处理过时间序列的同学们都不陌生,这货的用法很简单,下面是从帮助文档中摘的例子:
require(graphics)
## Generate a timeseries as a sample
ts(1:10, frequency = 4, start = c(1959, 2)) # 2nd Quarter of 1959
## Qtr1 Qtr2 Qtr3 Qtr4
## 1959 1 2 3
## 1960 4 5 6 7
## 1961 8 9 10
## Using July 1954 as start date:
gnp <- ts(cumsum(1 + round(rnorm(100), 2)),
start = c(1954, 7), frequency = 12)
plot(gnp) # using 'plot.ts' for time-series plot
acf(gnp)
pacf(gnp)
ts类型的对象的缺点显而易见:只适宜处理规则时间序列、没有独立的索引属性等等。基于种种缺点,能人纷们纷出手开发了另外几个R包,包括专门处理不规则时间序列的its包,能同时处理规则时间序列和不规则时间序列的tseries包,能从网络获取金融数据并具有独立时间属性的tseries包,还有本文标题中提到的zoo包。
zoo包出现在stat包、its包、tseries包和timeSeries包之后、在xts之前。那么,很多人会疑问,根据前面说的,its包、tseries包和timeSeries包已经很好的填补了stat包的诸多不足,为什么还要开发zoo包,这不是重复造轮子吗?还是它拥有独道的优点?这得回顾一下Zeileis开发zoo包的初衷。
话说,时间序列分析领域有一个很重要的方向是诊断时间序列的结构性变异。比如,研究某个时间序列是否在某个时点之后出现显著的结构性变化之类的。Zeileis原本想开发这么一个诊断时间序列结构性变异的R包,也就是后来的strucchange。但在开发strucchange包时需要用到一种能不依赖索引类型并严格排序的时序对象,注意“不依赖索引类型”、“严格排序”这些特性是以上所有时间序列对象类型没有满足的,于是,他只好自己着手构建满足自己需求的zoo对象和zoo包。这个包的名字就源自于Z’s ordered observations的首字母。
本篇笔记系统地说说zoo包的一些用法和特性。本文的结构如下:
- 1.zoo简介
- 1.1 zoo对象简介及创建
- 1.2 创建zooreg对象
- 1.3 基本运算
- 1.4 滚动计算
- 1.5 数据及索引的提取和替换
- 1.6 汇总描述
- 1.7 数据合并
- 1.8 缺失值处理
- 1.9 类型转化
- 1.10 zoo对象的绘图
- 2.实际案例
- 2.1 协同tseries包处理金融数据
- 2.2 使用timeDate类索引
- 2.3 创建yearmon和yearqtr类型
- 3.总结
- 4.资料推荐
1.zoo简介
1.1 zoo对象简介及创建
zoo包里面有两种基本的对象类型,一种是zoo,一种是zooreg。我们先创建一个zoo对象看看,创建zoo对象的基本命令是;
zoo(x,order.by)
其中,x是一个包含观测值的向量或者矩阵,order.by是x对应的排序后的索引。索引的长度必须跟x的长度或者行数一致。上述命令得到的zoo对象跟x看起来一样,不同的地方在于多了一个index属性,这个属性保存了zoo对象的索引信息。
理论上,x和order.by可以是任意类型,但x是数值型的情况比较常见,因为数值型情况下便于进行数学运算、建模及可视化。实际创建一些zoo对象:
library(zoo)
##
## 载入程序包:'zoo'
## The following objects are masked from 'package:base':
##
## as.Date, as.Date.numeric
set.seed(1071)
z1.index<-ISOdatetime(2014,rep(1:2,5),sample(28,10),0,0,0);
z1.data<-rnorm(10)
z1<-zoo(z1.data,z1.index)
z2.index<-as.POSIXct(paste(2014,rep(1:2,5),sample(1:28,10),sep="-"))
z2.data<-sin(2*1:10/pi)
z2<-zoo(z2.data,z2.index)
Z.index<-as.Date(sample(12450:12500,10));
Z.data<-matrix(rnorm(30),ncol=3);
colnames(Z.data)<-c("Aa","Bb","Cc");
Z<-zoo(Z.data,Z.index);
上面的这个as.Date是zoo包中的,等同于base包中的as.Date(origin=“1970-01-01”)。
真正操作数据时,通常要处理的数据已经包含了索引,用不着单独创建。
R中的很多函数比如print,summary,str,head,tail以及[ 能够对zoo对象进行操作。
要注意的是:向量型的zoo对象默认显示为行向量,而矩阵型的zoo对象默认为上下排列。
summary(z1)
## Index z1
## Min. :2014-01-05 00:00:00 Min. :-2.07608
## 1st Qu.:2014-01-14 18:00:00 1st Qu.:-1.04698
## Median :2014-01-25 00:00:00 Median : 0.24573
## Mean :2014-01-29 21:36:00 Mean :-0.01033
## 3rd Qu.:2014-02-17 12:00:00 3rd Qu.: 0.73163
## Max. :2014-02-26 00:00:00 Max. : 1.94079
summary(Z)
## Index Aa Bb Cc
## Min. :2004-02-10 Min. :-2.7384 Min. :-1.518622 Min. :-0.83789
## 1st Qu.:2004-02-19 1st Qu.:-0.1366 1st Qu.:-0.554268 1st Qu.:-0.61149
## Median :2004-03-04 Median : 0.3307 Median : 0.274825 Median :-0.07863
## Mean :2004-03-01 Mean : 0.2004 Mean : 0.006083 Mean : 0.12034
## 3rd Qu.:2004-03-09 3rd Qu.: 1.2433 3rd Qu.: 0.583592 3rd Qu.: 0.72902
## Max. :2004-03-22 Max. : 1.4238 Max. : 1.347743 Max. : 2.00417
1.2 创建zooreg对象
zoo对象本身就可以存储规则时间序列,而且stat包中本身也有存储规则时间序列的ts对象。为什么还要创建一个zooreg类型呢?有两个原因:一个是在将zoo对象转为ts对象时需要存储规则时间序列的频率,有了zooreg,可以在zoo对象和ts对象之间自由转换。再一个是因为对于ts对象,一旦出现缺失值,则其不再为规则时间序列,而zooreg可以存储有缺失值的规则时间序列。因此,我们可以把zooreg对象视为zoo的子对象,它继承了zoo对象的所有特性,并增加了frequency特性。
zoo(x,order.by,frequency)
zooreg(data,start,end,frequency,deltat,ts.eps,order.by)
在zoo中使用frequency参数时,函数会自动检查frequency跟order.by是否匹配,如果匹配,就返回一个zooreg对象。zooreg()函数的参数跟ts()函数的参数完全一致。zooreg(order.by)相当于是zoo(x,order.by,frequency)。
要注意的是:zooreg对象的索引类型有相对严格的要求,其必须能转化为numeric,因为函数要靠转化后的numeric对象来判断索引的规则与否。而且索引必须是1/frequency的整数倍。
zr1 <- zooreg(sin(1:9),start=2000,frequency=4)
zr2 <- zoo(sin(1:9),seq(2000,2002,by=1/4),4)
zr1
## 2000 Q1 2000 Q2 2000 Q3 2000 Q4 2001 Q1 2001 Q2 2001 Q3
## 0.8414710 0.9092974 0.1411200 -0.7568025 -0.9589243 -0.2794155 0.6569866
## 2001 Q4 2002 Q1
## 0.9893582 0.4121185
zr2
## 2000 Q1 2000 Q2 2000 Q3 2000 Q4 2001 Q1 2001 Q2 2001 Q3
## 0.8414710 0.9092974 0.1411200 -0.7568025 -0.9589243 -0.2794155 0.6569866
## 2001 Q4 2002 Q1
## 0.9893582 0.4121185
zooreg对象也能处理非数值型的索引,当然你得保证后续增加的观测值对应的索引类型也是非numerec,否则,索引类型将被强制转换。
zooreg(1:5,start=as.Date("2005-01-01"))
## 2005-01-01 2005-01-02 2005-01-03 2005-01-04 2005-01-05
## 1 2 3 4 5
可以用frequency,deltat,cycle,is.regular(x,stric=FALSE)函数来查看zooreg对象的信息。
frequency(zr1)
## [1] 4
deltat(zr1)
## [1] 0.25
cycle(zr1)
## 2000 Q1 2000 Q2 2000 Q3 2000 Q4 2001 Q1 2001 Q2 2001 Q3 2001 Q4 2002 Q1
## 1 2 3 4 1 2 3 4 1
is.regular(zr1)
## [1] TRUE
is.regular(zr1,strict=TRUE)
## [1] TRUE
这些函数对规则的zoo对象也适用。
zr1<- as.zoo(zr1)
zr1
## 2000 Q1 2000 Q2 2000 Q3 2000 Q4 2001 Q1 2001 Q2 2001 Q3
## 0.8414710 0.9092974 0.1411200 -0.7568025 -0.9589243 -0.2794155 0.6569866
## 2001 Q4 2002 Q1
## 0.9893582 0.4121185
class(zr1)
## [1] "zoo"
frequency(zr1)
## [1] 4
这种时间序列虽然看起来规则,但使用的时候难保不会出现差错儿。所以,能保存为zooreg就不要保存为zoo,时刻谨记座右铭:不作死就不会死。
上面说过,zooreg对象的优点是即使删除一个缺失值,仍然保持规则时间序列的性质。比如:
zr1 <- zr1[-c(3,5)]
zr1
## 2000 Q1 2000 Q2 2000 Q4 2001 Q2 2001 Q3 2001 Q4 2002 Q1
## 0.8414710 0.9092974 -0.7568025 -0.2794155 0.6569866 0.9893582 0.4121185
class(zr1)
## [1] "zoo"
frequency(zr1)
## [1] 4
与ts对象相比,zooreg在处理缺失值或者时间序列回归方面更胜一筹。像这种有缺失的规则时间序列叫弱规则时间序列,我们将这种时间序列强制转化为ts对象时,缺失值将表示为NA。而对于规则的时间序列,如果索引刚好是数值型,那么,我们可以在zoo和ts两者之间进行自由转换。
as.ts(zr1)
## Qtr1 Qtr2 Qtr3 Qtr4
## 2000 0.8414710 0.9092974 NA -0.7568025
## 2001 NA -0.2794155 0.6569866 0.9893582
## 2002 0.4121185
identical(zr2,as.zoo(as.ts(zr2)))
## [1] TRUE
因而,我们可以直接对zooreg对象使用acf,arima,stl等函数。
1.3 基本运算
对于维度一样的对象,直接计算即可。对于维度不一样的对象,会先计算对象索引的交集,在根据交集进行相关运算。
z1+z2
## 2014-01-14 2014-02-01 2014-02-26
## 0.2282647 -1.1200202 -0.7067490
z1<z2
## 2014-01-14 2014-02-01 2014-02-26
## FALSE TRUE FALSE
cumsum、cumprod、cummin、cummax等都是对列进行操作。
cumsum(Z)
## Aa Bb Cc
## 2004-02-10 1.255434 0.68157316 -0.63292049
## 2004-02-11 2.679232 -0.13457166 -1.18011092
## 2004-02-18 2.802320 -1.65319323 -1.95318901
## 2004-02-22 3.340710 -1.42183190 0.05098188
## 2004-03-04 4.547665 -1.10368968 0.03968985
## 2004-03-05 1.809245 -0.87218273 -0.79819889
## 2004-03-08 1.663859 -0.41983370 -0.94417290
## 2004-03-10 2.987271 -1.91425639 -0.89375702
## 2004-03-21 2.113978 -1.28691668 0.24816234
## 2004-03-22 2.003582 0.06082586 1.20338703
也可以计算zoo对象的滞后和差分。
lag(z2,k=-1)
## 2014-01-13 2014-01-14 2014-01-19 2014-01-20 2014-02-01 2014-02-08
## 0.94306673 -0.52575918 -0.04149429 0.59448077 -0.96739776 0.95605566
## 2014-02-10 2014-02-22 2014-02-26
## 0.56060280 0.08291711 -0.62733473
merge(z1,lag(z1,k=1))
## z1 lag(z1, k = 1)
## 2014-01-05 0.02107873 0.7467599
## 2014-01-07 0.74675994 0.2697590
## 2014-01-14 0.26975895 0.6862577
## 2014-01-17 0.68625772 1.9407885
## 2014-01-18 1.94078850 -2.0760758
## 2014-02-01 -2.07607585 -1.7843924
## 2014-02-13 -1.78439244 -1.4029994
## 2014-02-19 -1.40299938 1.2738445
## 2014-02-24 1.27384445 0.2217044
## 2014-02-26 0.22170438 NA
diff(z1)
## 2014-01-07 2014-01-14 2014-01-17 2014-01-18 2014-02-01 2014-02-13 2014-02-19
## 0.7256812 -0.4770010 0.4164988 1.2545308 -4.0168643 0.2916834 0.3813931
## 2014-02-24 2014-02-26
## 2.6768438 -1.0521401
1.4 滚动计算
处理时间序列是经常用到滚动计算,比如,要滚动计算任意n天的均值、方差等等。zoo包里面提供了rollapply函数来完成这个操作。基本用法是;
rollapply(data, width, FUN)
这里的data是操作对象,width是滚动的窗口宽度,FUN是对每一个窗口的数据执行的具体函数。比如:
rollapply(Z,5,sd)
## Aa Bb Cc
## 2004-02-18 0.5542603 0.9148719 1.1526241
## 2004-02-22 1.6753029 0.8212506 1.1843236
## 2004-03-04 1.5062902 0.8220241 1.1539834
## 2004-03-05 1.6591613 0.8112685 1.0628096
## 2004-03-08 1.6725661 0.8635166 0.7110273
## 2004-03-10 1.4791770 1.0524092 0.8172367
有些观测值被删除了,因为那些观测值没法占满窗口。我们可以通过设置fill=TRUE用NA来填充这些位置。
rollapply(Z,5,sd,align="left",fill=TRUE)
## Aa Bb Cc
## 2004-02-10 0.5542603 0.9148719 1.1526241
## 2004-02-11 1.6753029 0.8212506 1.1843236
## 2004-02-18 1.5062902 0.8220241 1.1539834
## 2004-02-22 1.6591613 0.8112685 1.0628096
## 2004-03-04 1.6725661 0.8635166 0.7110273
## 2004-03-05 1.4791770 1.0524092 0.8172367
## 2004-03-08 1.0000000 1.0000000 1.0000000
## 2004-03-10 1.0000000 1.0000000 1.0000000
## 2004-03-21 1.0000000 1.0000000 1.0000000
## 2004-03-22 1.0000000 1.0000000 1.0000000
填补方式分为左填补、右填补和居中填补。
rollapply(Z,5,sd,align="left",fill = TRUE)
## Aa Bb Cc
## 2004-02-10 0.5542603 0.9148719 1.1526241
## 2004-02-11 1.6753029 0.8212506 1.1843236
## 2004-02-18 1.5062902 0.8220241 1.1539834
## 2004-02-22 1.6591613 0.8112685 1.0628096
## 2004-03-04 1.6725661 0.8635166 0.7110273
## 2004-03-05 1.4791770 1.0524092 0.8172367
## 2004-03-08 1.0000000 1.0000000 1.0000000
## 2004-03-10 1.0000000 1.0000000 1.0000000
## 2004-03-21 1.0000000 1.0000000 1.0000000
## 2004-03-22 1.0000000 1.0000000 1.0000000
对于一些常用的滚动计算,比如,rollapply(data,width,mean),rollapply(data,width,max)等,zoo提供了rollmean(x,k)、rollmax(x,k),rollmedian(x,k)等函数。
rollmean(z2,5,fill=TRUE)
## 2014-01-06 2014-01-13 2014-01-14 2014-01-19 2014-01-20 2014-02-01
## 1.0000000000 1.0000000000 0.0005792538 0.0031770388 0.2204494347 0.2453317148
## 2014-02-08 2014-02-10 2014-02-22 2014-02-26
## 0.0009686142 0.0087574946 1.0000000000 1.0000000000
1.5 数据及索引的提取和替换
coredata函数可以提取zoo对象的数据。类似于its包中的core函数及tseries包中的value函数。
library(xts)
coredata(z1)
## [1] 0.02107873 0.74675994 0.26975895 0.68625772 1.94078850 -2.07607585
## [7] -1.78439244 -1.40299938 1.27384445 0.22170438
index函数可以提取zoo对象的索引。
index(z2)
## [1] "2014-01-06 CST" "2014-01-13 CST" "2014-01-14 CST" "2014-01-19 CST"
## [5] "2014-01-20 CST" "2014-02-01 CST" "2014-02-08 CST" "2014-02-10 CST"
## [9] "2014-02-22 CST" "2014-02-26 CST"
index(z2) <- index(z1)
time函数与index函数类似。
time(z1)
## [1] "2014-01-05 CST" "2014-01-07 CST" "2014-01-14 CST" "2014-01-17 CST"
## [5] "2014-01-18 CST" "2014-02-01 CST" "2014-02-13 CST" "2014-02-19 CST"
## [9] "2014-02-24 CST" "2014-02-26 CST"
start和end函数可以提取第一个和最后一个索引。
抽取zoo对象的子集可以通过[或者window来进行。
Z[1:3,2:3]
## Bb Cc
## 2004-02-10 0.6815732 -0.6329205
## 2004-02-11 -0.8161448 -0.5471904
## 2004-02-18 -1.5186216 -0.7730781
也可以用[加索引来选取Z的子集。
z1[ISOdatetime(2004,1,c(14,25),0,0,0)]
## Data:
## numeric(0)
##
## Index:
## POSIXct of length 0
如果索引的类型是numeric的话,在代码用需要用I来保护,此时相应的代码为Z[I(i)]。或者用window。
window函数的用法如下:
window(x,index,start,end)
x是zoo对象,index是索引的子集,end和start用来进一步约束索引的子集。
window(Z,start=as.Date("2004-03-01")) # 选出2004-3-1以来的所有观测值
## Aa Bb Cc
## 2004-03-04 1.2069552 0.3181422 -0.01129202
## 2004-03-05 -2.7384202 0.2315069 -0.83788874
## 2004-03-08 -0.1453861 0.4523490 -0.14597401
## 2004-03-10 1.3234122 -1.4944227 0.05041588
## 2004-03-21 -0.8732929 0.6273397 1.14191937
## 2004-03-22 -0.1103956 1.3477425 0.95522468
window(Z,index=index(Z)[5:8],end=as.Date("2004-03-01")) # 选出第5至第8个观测值中,不晚于2004-3-1的观测值
## Aa Bb Cc
也可以用来替换观测值。
window(z1,end=as.POSIXct("2004-02-01"))<-9:5
1.6 汇总描述
aggregate可以对zoo对象进行汇总。说人话就是zoo会根据某一列的取值将zoo对象切割为几个独立的子集。再对每个子集执行指定的函数。
对于Z来说,我们可以按月份对其其均值。这个过程需要两步,第一步是将Z的索引划分为月份,第二步是分组汇总。
firstofmonth <- function(x){as.Date(sub("..$","01",format(x)))}
index(Z)<-firstofmonth(index(Z)) # 将日期统一为当月首日日期
aggregate(Z,index(Z),mean)
## Aa Bb Cc
## 2004-02-01 0.8351775 -0.3554580 0.01274547
## 2004-03-01 -0.2228546 0.2471096 0.19206753
aggregate(Z,firstofmonth,head,1)
## Aa Bb Cc
## 2004-02-01 1.255434 0.6815732 -0.63292049
## 2004-03-01 1.206955 0.3181422 -0.01129202
与汇总相反的是数据还原,通常是借助插值来实现的。比如,Nile是ts类型的年度数据,我们可以将其转换为zoo类型的季度数据,并用na.approx,na.locf和na.spline来进行差值。
Nile.na<-merge(as.zoo(Nile),zoo(,seq(start(Nile)[1],end(Nile)[1],1/4)))
head(as.zoo(Nile))
## 1871 1872 1873 1874 1875 1876
## 1120 1160 963 1210 1160 1160
head(na.approx(Nile.na))
## 1871(1) 1871(2) 1871(3) 1871(4) 1872(1) 1872(2)
## 1120.00 1130.00 1140.00 1150.00 1160.00 1110.75
head(na.locf(Nile.na))
## 1871(1) 1871(2) 1871(3) 1871(4) 1872(1) 1872(2)
## 1120 1120 1120 1120 1160 1160
head(na.spline(Nile.na))
## 1871(1) 1871(2) 1871(3) 1871(4) 1872(1) 1872(2)
## 1120.000 1199.059 1224.985 1208.419 1160.000 1091.970
1.7 数据合并
可用rbind函数来对zoo对象进行行合并,此时,合并前的对象必须有相同的列数,并且索引不能有重合。
rbind(z1[2:3],z1[5:10]) # 正常行合并
## 2014-01-07 2014-01-14 2014-01-18 2014-02-01 2014-02-13 2014-02-19 2014-02-24
## 0.7467599 0.2697590 1.9407885 -2.0760758 -1.7843924 -1.4029994 1.2738445
## 2014-02-26
## 0.2217044
# rbind(z1[2:5],z1[5:10]) # 索引重合会报错
c函数跟rbind函数的作用相同。
c(z1[2:3],z1[5:10])
## 2014-01-07 2014-01-14 2014-01-18 2014-02-01 2014-02-13 2014-02-19 2014-02-24
## 0.7467599 0.2697590 1.9407885 -2.0760758 -1.7843924 -1.4029994 1.2738445
## 2014-02-26
## 0.2217044
cbind函数可以对zoo对象进行列合并。
cbind(z1,z2)
## z1 z2
## 2014-01-05 0.02107873 0.94306673
## 2014-01-07 0.74675994 -0.52575918
## 2014-01-14 0.26975895 -0.04149429
## 2014-01-17 0.68625772 0.59448077
## 2014-01-18 1.94078850 -0.96739776
## 2014-02-01 -2.07607585 0.95605566
## 2014-02-13 -1.78439244 0.56060280
## 2014-02-19 -1.40299938 0.08291711
## 2014-02-24 1.27384445 -0.62733473
## 2014-02-26 0.22170438 -0.92845336
这个函数实质上是以两个对象的索引的并集作为结果对象的索引,这样一来会出现缺失值,当然它们的位置会填充为NA。下面的命令与上面的命令结果相同;
merge(z1,z2,all=TRUE)
## z1 z2
## 2014-01-05 0.02107873 0.94306673
## 2014-01-07 0.74675994 -0.52575918
## 2014-01-14 0.26975895 -0.04149429
## 2014-01-17 0.68625772 0.59448077
## 2014-01-18 1.94078850 -0.96739776
## 2014-02-01 -2.07607585 0.95605566
## 2014-02-13 -1.78439244 0.56060280
## 2014-02-19 -1.40299938 0.08291711
## 2014-02-24 1.27384445 -0.62733473
## 2014-02-26 0.22170438 -0.92845336
但merge可以提供更多的可用参数。比如,可以指定缺失值的填充方式,可以调整合并对象的列名,也可以指定返回结果的类型。
如果merge的对象中有zooreg对象,则merge的结果将是zooreg对象。在这个过程中,merge会在幕后默默的判断时间序列的频率,并检查时间序列规则与否。如果merge的对象中有非zoo对象,那么,merge会毫不犹豫地把zoo对象的索引加到其它对象身上。
如果merge的对象中,索引的类型不一样,R一般会给出警告,并尝试将索引强制转换为一致。我们不鼓励用merge合并索引类型不同的对象,否则,后果自负。
1.8 缺失值处理
na.omit,na.contiguous,na.approx,na.locf,na.omit和na.spline都能来处理缺失值。na.omit的作用是剔除缺失值。
z1[sample(1:10,3)] <- NA
z1
## 2014-01-05 2014-01-07 2014-01-14 2014-01-17 2014-01-18 2014-02-01 2014-02-13
## NA 0.7467599 0.2697590 0.6862577 1.9407885 -2.0760758 NA
## 2014-02-19 2014-02-24 2014-02-26
## -1.4029994 NA 0.2217044
na.omit(z1)
## 2014-01-07 2014-01-14 2014-01-17 2014-01-18 2014-02-01 2014-02-19 2014-02-26
## 0.7467599 0.2697590 0.6862577 1.9407885 -2.0760758 -1.4029994 0.2217044
na.contiguous函数是返回对象中没有不包含缺失值的最长片段。
na.contiguous(z1)
## 2014-01-07 2014-01-14 2014-01-17 2014-01-18 2014-02-01
## 0.7467599 0.2697590 0.6862577 1.9407885 -2.0760758
na.approx函数是用approx函数对缺失值进行线性差值
na.approx(z1)
## 2014-01-07 2014-01-14 2014-01-17 2014-01-18 2014-02-01 2014-02-13 2014-02-19
## 0.7467599 0.2697590 0.6862577 1.9407885 -2.0760758 -1.6273582 -1.4029994
## 2014-02-24 2014-02-26
## -0.2424967 0.2217044
默认情况下na.approx函数基于时间序列的时间跨度进行插值。它跟下面的情况有所不同。
na.approx(z1,1:NROW(z1))
## 2014-01-07 2014-01-14 2014-01-17 2014-01-18 2014-02-01 2014-02-13 2014-02-19
## 0.7467599 0.2697590 0.6862577 1.9407885 -2.0760758 -1.7395376 -1.4029994
## 2014-02-24 2014-02-26
## -0.5906475 0.2217044
设置na.approx的第二个参数,可以按照需要对缺失值进行插值。
na.lcof是用前值替代法进行插值。
na.locf(z1)
## 2014-01-07 2014-01-14 2014-01-17 2014-01-18 2014-02-01 2014-02-13 2014-02-19
## 0.7467599 0.2697590 0.6862577 1.9407885 -2.0760758 -2.0760758 -1.4029994
## 2014-02-24 2014-02-26
## -1.4029994 0.2217044
1.9 类型转化
R中的很多对象都可以跟zoo进行自由转换。尤其是ts,irts,its等对象,很容易就可以转化为zoo对象。如果索引正确,还可以将zoo对象转化回去。zoo对象和zooreg对象之间的转化更方便,无非是增加或者删除frequency属性。除此之外,zoo对象还可以转化为向量、矩阵、列表和数据框,要注意的是转为数据框时索引属性会丢掉,但实质内容还是保留完整的。
as.data.frame(Z)
## Aa Bb Cc
## 1 1.2554339 0.6815732 -0.63292049
## 2 1.4237978 -0.8161448 -0.54719043
## 3 0.1230887 -1.5186216 -0.77307809
## 4 0.5383894 0.2313613 2.00417089
## 5 1.2069552 0.3181422 -0.01129202
## 6 -2.7384202 0.2315069 -0.83788874
## 7 -0.1453861 0.4523490 -0.14597401
## 8 1.3234122 -1.4944227 0.05041588
## 9 -0.8732929 0.6273397 1.14191937
## 10 -0.1103956 1.3477425 0.95522468
1.10 zoo对象的绘图
zoo对象的绘图要依赖于plot和lines函数。
plot(Z)
## Warning in zoo(rval, index(x)[i]): some methods for "zoo" objects do not work
## if the index entries in 'order.by' are not unique
## Warning in zoo(rval, index(x)[i]): some methods for "zoo" objects do not work
## if the index entries in 'order.by' are not unique
## Warning in zoo(rval, index(x)[i]): some methods for "zoo" objects do not work
## if the index entries in 'order.by' are not unique
## Warning in zoo(rval, index(x)[i]): some methods for "zoo" objects do not work
## if the index entries in 'order.by' are not unique
## Warning in zoo(rval, index(x)[i]): some methods for "zoo" objects do not work
## if the index entries in 'order.by' are not unique
## Warning in zoo(rval, index(x)[i]): some methods for "zoo" objects do not work
## if the index entries in 'order.by' are not unique
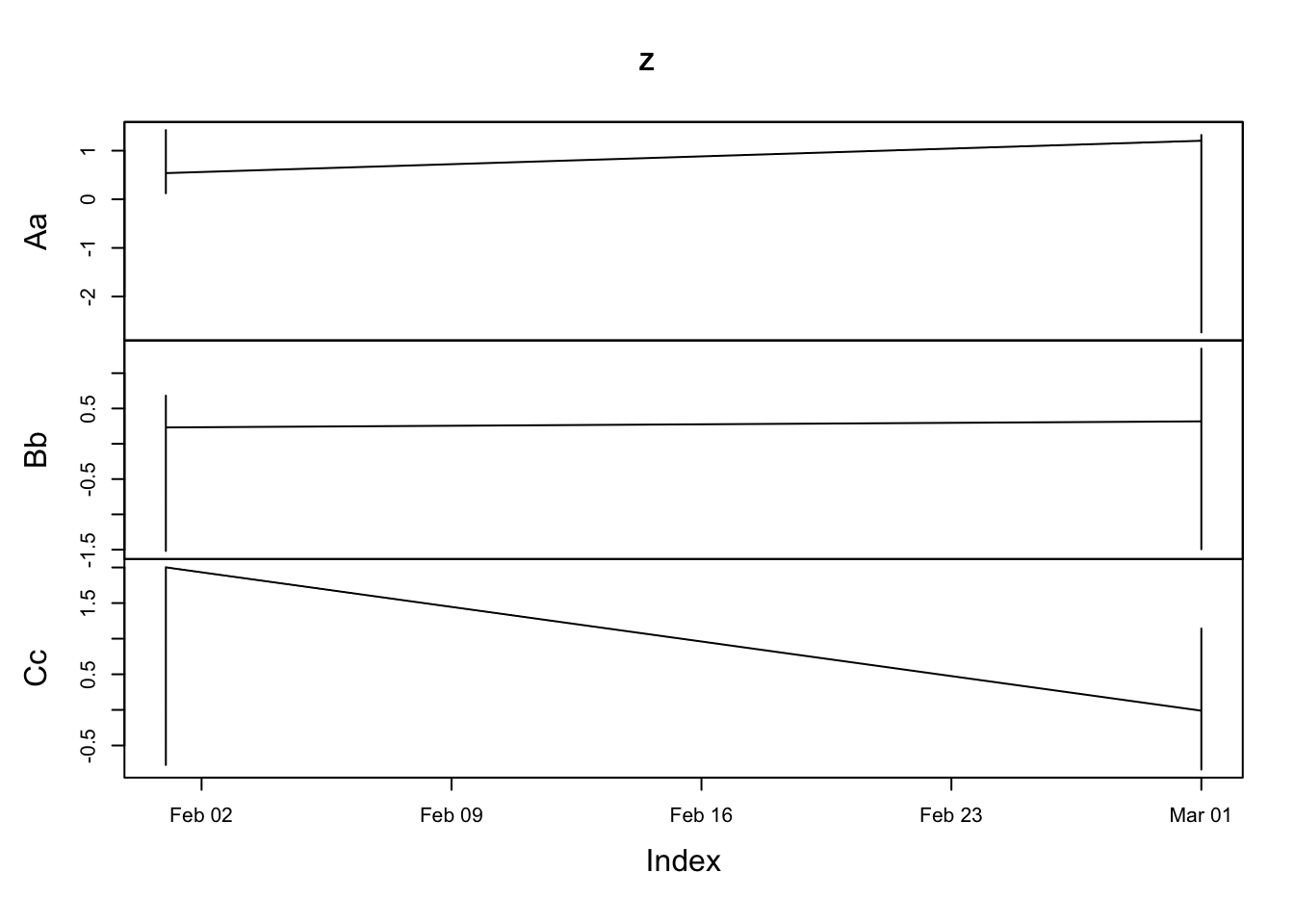
图中,横轴是索引,纵轴是时间序列对应的取值。也可以将多条时间序列画到同一个面板上。
plot(Z,plot.type="single",col=2:4)
我们可以指定col,pch等参数。这儿有一个不同之处,即zoo允许我们通过list指定这些参数,并且提供了自动补全功能。比如:
plot(Z,type="b",lty=1:3,pch=list(Aa=1,Bb=2,Cc=4),col=list(Bb=2,4),plot.type="single")
zoo与其它包的协同
strucchange:实证波动过程
strucchange包是用来检验、计量数据或者模型尤其是线性回归模型中的结构变异点的一个包。在检验过程中通常要看模型参数是否随着某个排序变量(通常是时间)的变化而有所改变。在这个过程中,需要用到严格排序的带索引的时间序列。正是这一需求促使作者开发了zoo包。
下面以strucchange包为例演示一下zoo包的用法。这里用到的数据fruitohms在DAAG包中。该数据包含的是奇异果的果汁含量数据和奇异果本身电阻大小的测量值。要研究的问题则是,奇异果的电阻大小是否随着奇异果果汁含量的多寡有显著改变。我们可以用基于最小二乘的累加检验来验证这个问题,但在检验过程中要对按照果汁含量的多寡对数据进行严格排序,而这是其它类型的时序对象无法实现的。相应的代码如下:
library(strucchange)
## 载入需要的程序包:sandwich
library(DAAG)
data("fruitohms")
ocus <- gefp(ohms ~ 1,order.by=~juice,data=fruitohms)
使用plot函数绘制ocus的图形,得到图3。
plot(ocus)
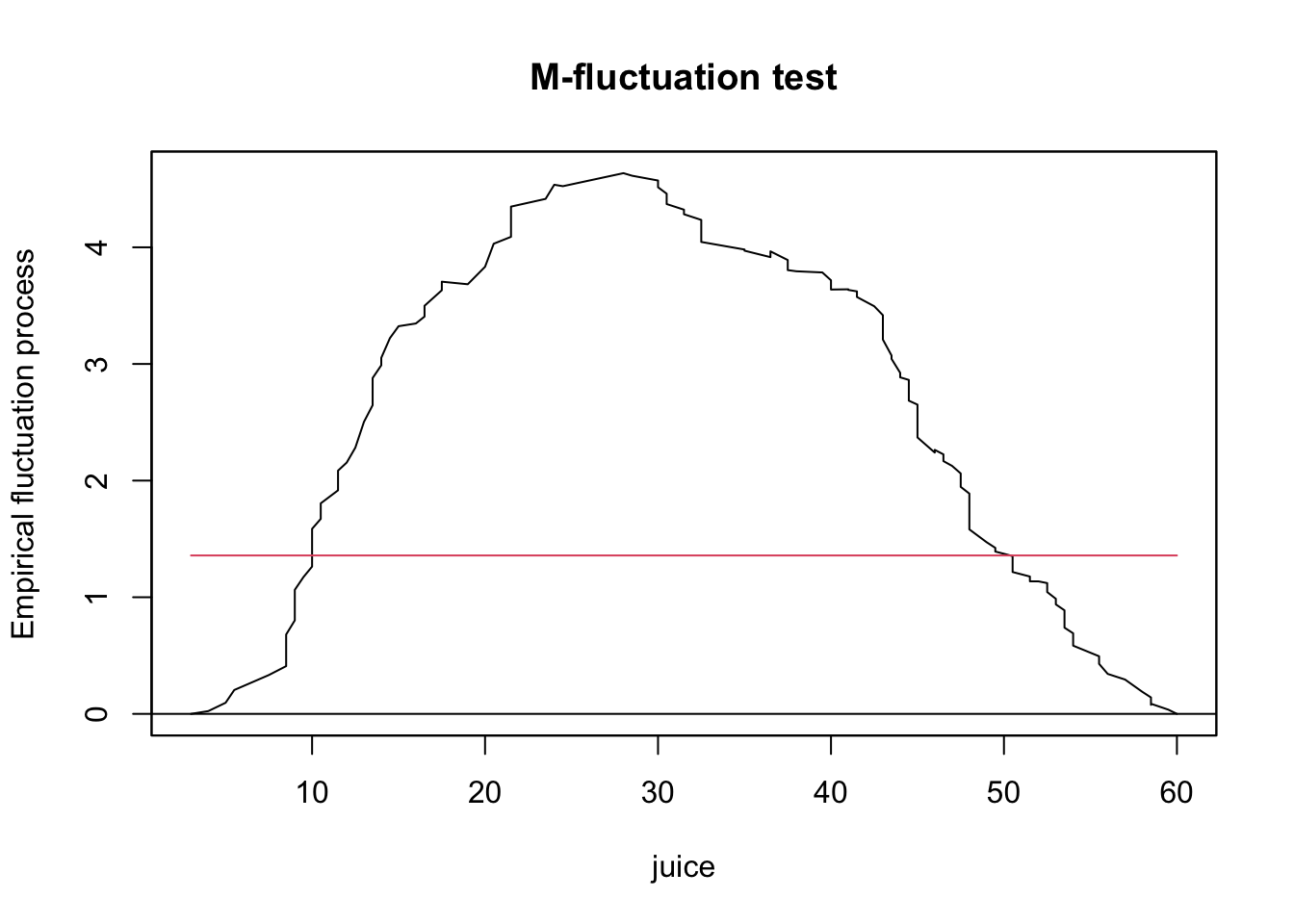
从图上可以看出,检验结果超出了5%的临界值,这意味着随着果汁含量多寡的不同,奇异果的平均电阻值发生了显著的变化。
上述代码中得到的ocus对象本身是基于zoo对象进行构建的,并且绘图过程实际上是调用了针对gefp对象的专属绘图方法。
2. 实际案例
2.1 协同tseries包处理金融数据
tseries包中的get.hist.quote函数可以通过访问Yahoo!的在线金融数据库来获取路透社提供的金融数据。比如,用下面的代码可以获得微软公司在2011-01-01到2014-04-30日期间的日交易数据:
library("tseries")
## Registered S3 method overwritten by 'quantmod':
## method from
## as.zoo.data.frame zoo
MSFT <- get.hist.quote(instrument="MSFT",start="2011-01-01",end="2014-04-30",origin="1970-01-01")
## time series starts 2011-01-03
## time series ends 2014-04-29
在返回的MSFT中,带缺失值的时间序列被填充为规则时间序列,并用NA对缺失位置进行填充。这里的索引类型是Date,其存储形式为数值型,该数值等于距离某个origin的天数。上例中origin=“1970-01-01”。
也可以令结果返回为ts格式。
MSFT <- get.hist.quote(instrument="MSFT",start="2011-01-01",end="2014-04-30",origin="1970-01-01",retclass="ts")
## time series starts 2011-01-03
## time series ends 2014-04-29
我们可以将ts对象转化为索引类型为Date的zoo对象。
MSFT <- as.zoo(MSFT)
index(MSFT) <- as.Date(index(MSFT))
MSFT <- na.omit(MSFT)
这里的交易数据是日交易数据,因此隐含的是规则时间序列。所以,第一次as.zoo的对象返回的是zooreg对象,要想将其转换为彻底的zoo对象,需要再次执行as.zoo()。
图4显示了zoo对象的绘图结果。
plot(diff(log(MSFT)))
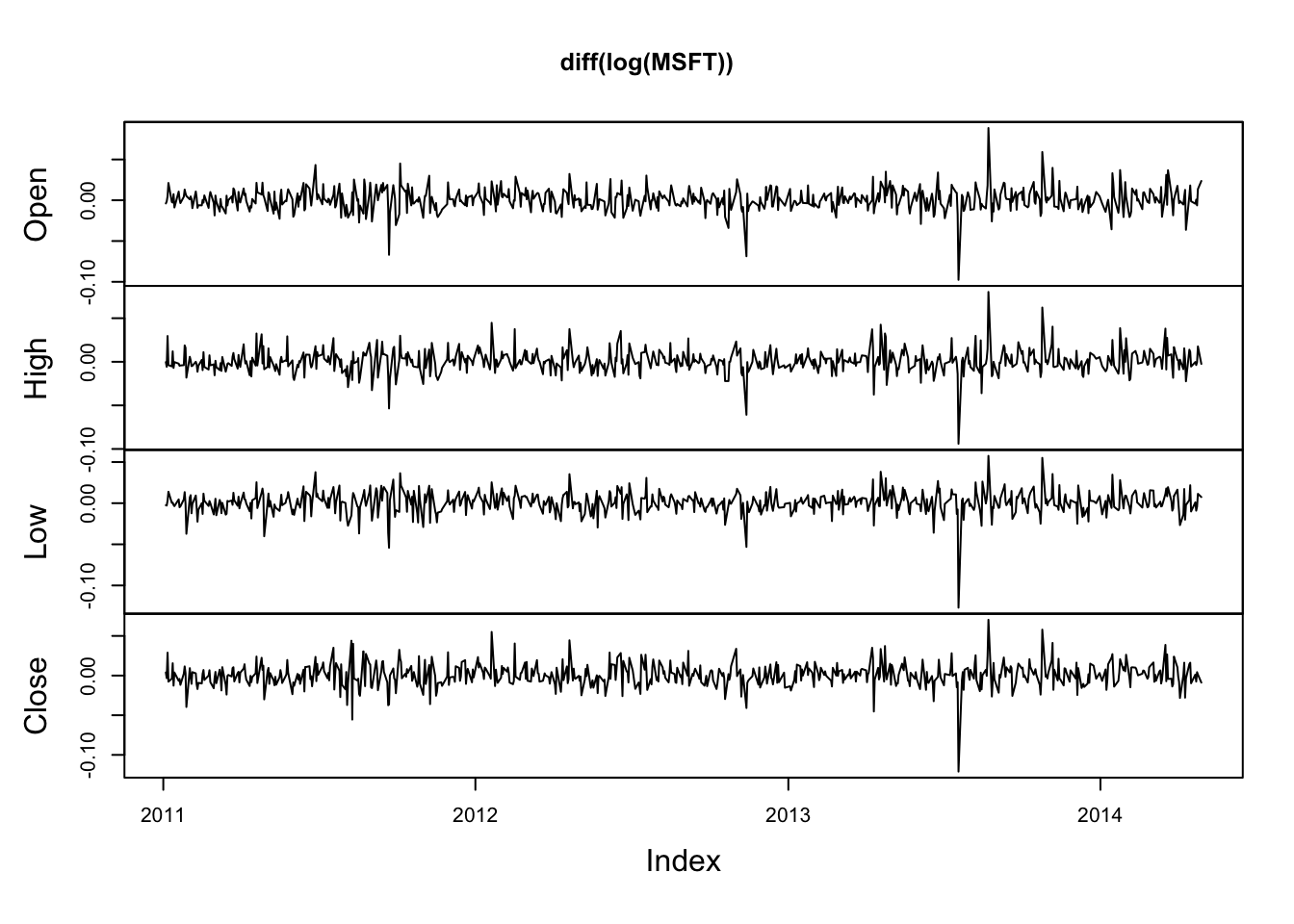
图4:微软公司集合收益率序列图
2.2 使用timeDate类索引
zoo对象可以引用timeDate的日期对象作为索引。虽然zoo包的方法可以针对多种索引类型进行操作。但一些特殊的索引类型仍然有必要提供c()、length()、[、ORDER()和MATCH()等方法来确保zoo类方法的正常执行。像timeDate就是其中之一。事实上,timeDate对象天然支持c()、length()和[;而zoo则天然支持ORDER()和MATCH()。两者相加可谓珠联璧合。要说的是,ORDER()和MATCH()在执行过程中会现将对象强制转换为POSIXct,再调用相应的方法进行操作。
下面的代码演示了如何将Z2的索引转换为timeDate类型。
library(timeDate)
z2td <- zoo(coredata(z2),timeDate(index(z2),FinCenter = "GMT"))
z2td
## 2014-01-04 16:00:00 2014-01-06 16:00:00 2014-01-13 16:00:00 2014-01-16 16:00:00
## 0.94306673 -0.52575918 -0.04149429 0.59448077
## 2014-01-17 16:00:00 2014-01-31 16:00:00 2014-02-12 16:00:00 2014-02-18 16:00:00
## -0.96739776 0.95605566 0.56060280 0.08291711
## 2014-02-23 16:00:00 2014-02-25 16:00:00
## -0.62733473 -0.92845336
2.3 创建yearmon和yearqtr类型
zoo包最强大的功能之一是能够对间序列对象的索引类型进行自定义。前面介绍了如何将一种已经存在的时间对象,比如,timeDate对象作为zoo对象的索引。下面介绍一下如何根据需要创建新的索引类型,比如可以创建yearmon和yearqtr等,很明显,这两个货分别针对月度和季度时间序列对象的专有索引。事实上,我们可以利用ts对象将月度时序数据的索引存储为数值型。但这么做的问题在于,该操作得到的结果并未包括时序数据本身为月度型数据的任何信息。而以yearmon类日期作为索引,由于yearmon类日期多了一个yearmon的属性,因而,可以明白的看出来这一点。创建yearmon对象的代码如下:
yearmon <- function(x) structure(floor(12*x + .0001)/12,class="yearmon")
与as.yearmon类似。
我们可以将yearmon对象转换为其它尺度的日期对象,比如,yearqtr代表的季度数据或者Date、POSIXlt和POSIXct等更小尺度的数据。这几个数据通常与yearmon数据的首日具有对应关系。format和as.character函数则可以将日期类函数迅速转化为文本格式。Ops和MATCH函数则可以则进一步完善了zoo包对月度日期对象的操作。
这些函数看起来并不起眼,但作用大大的。我们先创建一个叫zr3的规则时序对象,让其以yearmon对象作为索引,并与前面的zr1和zr2进行比较,显示结果更为简洁。
zr3 <- zooreg(rnorm(9),start=as.yearmon(2000),frequency=12)
zr3
## 1 2000 2 2000 3 2000 4 2000 5 2000 6 2000 7 2000
## -1.4221193 -0.8232956 0.1711008 1.0191386 0.3027276 -0.4975404 -2.0038764
## 8 2000 9 2000
## -1.1892796 -0.3388062
下面的代码可以将其汇总为季度数据。
aggregate(zr3,as.yearqtr,mean)
## 2000 Q1 2000 Q2 2000 Q3
## -0.6914380 0.2747753 -1.1773207
也可以将索引转化为Date类型的日期变量。默认情况下,会将月份转换为月份对应的第一天。
as.Date(index(zr3))
## [1] "2000-01-01" "2000-02-01" "2000-03-01" "2000-04-01" "2000-05-01"
## [6] "2000-06-01" "2000-07-01" "2000-08-01" "2000-09-01"
也可以修改参数转换为月度的最后一天。
as.Date(index(zr3),frac=1)
## [1] "2000-01-31" "2000-02-29" "2000-03-31" "2000-04-30" "2000-05-31"
## [6] "2000-06-30" "2000-07-31" "2000-08-31" "2000-09-30"
除此之外,可以将yearmon强制转化为POSIXct,以方便我们将时序对象导出为its或者irts。
index(zr3)<-as.POSIXct(index(zr3))
as.irts(zr3)
## 2000-01-01 00:00:00 GMT -1.422
## 2000-02-01 00:00:00 GMT -0.8233
## 2000-03-01 00:00:00 GMT 0.1711
## 2000-04-01 00:00:00 GMT 1.019
## 2000-05-01 00:00:00 GMT 0.3027
## 2000-06-01 00:00:00 GMT -0.4975
## 2000-07-01 00:00:00 GMT -2.004
## 2000-08-01 00:00:00 GMT -1.189
## 2000-09-01 00:00:00 GMT -0.3388
可以看出,在zoo中对时序对象的索引尺度和类型进行转换方便至极。
3. 总结
zoo包是一个基于R中的S3类构建的一个R包,用来处理严格排序且带索引的时间序列,包括规则时间序列和不规则时间序列。zoo包的设计宗旨是构造一个独立于索引类型的时序对象,并比照古典的ts对象开发相应的泛型方法。
上面的笔记我们简单的概括了zoo包的技术细节,并举例演示了zoo对象的绘图、合并、数学运算、数据提取、索引提取、缺失值处理等内容。事实上,我们可以简单地把zoo对象视为一个数据加索引的对象,其中,数据可以是向量或者矩阵,而索引则可以是任意类型的向量。对于特殊的zooreg对象,则还包括了frequency属性。zoo对象与其它时序对象比如ts、its、irts和timeSeries等可以自由转换,其填补了规则时间序列和不规则时间序列之间的隔膜。与经典的ts对象比较,可以更方便地处理缺失值。以上所说种种优点,使得我们可以进一步基于zoo对象构建新的时序类型或者应用。比如,quantmod中使用的xts类型就是基于zoo对象所构建的。但zoo包也有自身的缺点,即目前zoo对象的数据部分只能很好地支持数值型的向量或者矩阵,部分地支持带索引的因子型变量,对数据框、列表则支持的不够,但这些对象显然也能被索引化,这些应该是未来值得改进的地方。
4. 推荐文献
zoo:An S3 Class and Methods for Indexed Totally Ordered Observations